Code Vulnerability Detection: A Comparative Analysis of Emerging Large Language Models
Part1. title&Source
Title: Code Vulnerability Detection: A Comparative Analysis of Emerging Large Language Models
Source: 2024 preprint
Part2. abstract
本文探讨了在软件开发中,随着对开源项目依赖的增加,软件漏洞的数量呈现上升趋势。论文比较了几种新兴的大型语言模型(LLMs),如Llama, CodeLlama, Gemma, CodeGemma,与现有的先进模型BERT, RoBERTa, GPT-3的漏洞检测性能。研究发现,在检测软件漏洞方面,CodeGemma 的 F1-score 达到 58%,召回率为 87%,在新兴模型中表现最佳。
Part3. introduction
随着现代软件开发对开源项目的依赖性增强,潜在漏洞的风险也随之增加。开源项目的广泛使用使开发变得更快,但也带来了更多的安全隐患,这些漏洞容易被攻击者利用,带来严重的经济和社会影响。因此,代码漏洞检测已成为确保软件系统安全的重要环节。
传统方法如静态和动态分析虽有助于发现漏洞,但其在处理未知漏洞时存在局限。深度依赖网络的复杂软件生态系统进一步增加了漏洞检测的难度。近年来,大型语言模型(LLMs),尤其是BERT, GPT 和 T5 系列模型,展示了极高的上下文敏感度及漏洞指示符检测能力。本研究的主要目的是比较 Llama 和 Gemma 系列 LLMs 与现有的先进模型(如BERT, RoBERTa, GPT-3)的漏洞检测能力,并提出四个研究问题,探讨新兴 LLMs 在代码漏洞检测中的潜力。
RQ1:最新的大型语言模型在检测代码漏洞方面的效果如何
- lama 2、Gemma、CodeLlama、CodeGemma
RQ2:基于自然语言的 LLM 在这方面是否优于基于代码的 LLM
- 比较基于自然语言的 LLM(Llama 2、Gemma)和基于代码的 LLM 的性能(CodeLlama CodeGemma)
RQ3:比较的结果如何
RQ4:与现有的 LLM 相比,这些新的 LLM 的发现是什么
Part4. conclusion
研究表明,尽管新兴的LLMs在某些方面表现出色,如CodeGemma在召回率和F1-score方面表现突出,但其整体表现仍存在不确定性。Llama 2 在准确率上领先,但在某些情况下,模型的表现可能与预期不符,提示这些模型在特定任务中仍有待改进。此外,本研究强调了在不同任务中独立评估LLMs性能的重要性,而不能仅依赖其在一般任务中的优异表现。
Part5. related work
相关研究综述了几类与漏洞检测相关的工作:
数据集:
DiverseVul是当前最大、最新的漏洞源代码数据集,包含C/C++代码,涵盖150种常见弱点枚举(CWE)。其他数据集如Chakraborty等人的数据集,主要涵盖Android项目中的漏洞,但由于其复杂性并未被本研究采用。
传统检测方法:
静态分析工具在覆盖率和编程语言的支持方面存在局限,且常出现高假阳性率。
深度学习检测方法:
近年来,深度学习技术在漏洞检测中的应用取得了一定成果。尤其是图神经网络(GNN)等技术表现出色。
LLM检测:
最近的研究表明,LLMs在漏洞检测中的表现优异,尤其是GPT-3.5和GPT-4展示出强大的竞争力。
Part6. Approach
数据集收集和准备
使用Diversevul作为数据集,使用了预处理技术,包括分词化、归一化和数据增强,以确保数据集的整洁性和均匀性。数据集包含 Function、Target、CWE、Project、Commit id、Hash、Size 和 Message 等 8 列
function 显示 18945 个可能存在漏洞的代码片段。target显示该代码是否包含漏洞“1”表示易受攻击,“0”表示不易受攻击。CWE 是 CWE 编号,表示代码属于哪个类别的安全漏洞。Project 和 Commit ID 总共有 797 个项目 ID 和 7514 个提交,从中收集代码。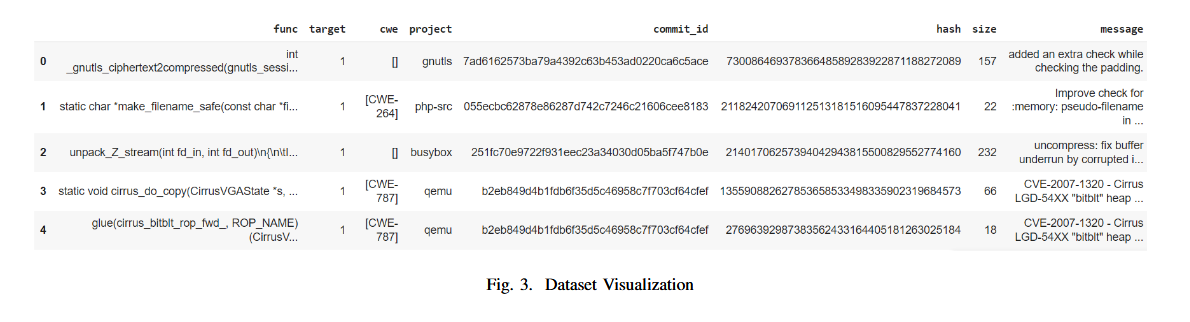
处理类不平衡
DiverseVul 数据集是一个高度不平衡的数据集,具有 150 个 CWE 类别。不平衡的类分布显示有 18945 个易受攻击的标记函数和 311547 个非易受攻击的函数。作者使用RandomUnderSampler方法,通过从多数类中随机删除样本来解决此问题,直到类分布变得更加平衡。参数 ‘sampling strategy’ 设置为 1,这意味着 minority 类中的样本数将等于重采样后 majority 类中的样本数。最后得到一个平衡的数据集,其中包含 330k 数据中的 37k 个样本。最后进行微调,在平衡数据集中为 Llama 采集了 1000 个样本,为 Gemma 采集了 3000 个样本,并进行了拆分,使 80% 的数据用于微调,20% 的数据用于测试
Prompt Engineering
提示工程是一种通过向 LLM 提供有关生成哪种数据的具体指示来控制 LLM 输出的方法。依赖于精确设计的promot,Llama 2 使用系统消息进行训练,该消息设置解决任务时要假设的上下文和角色,所以需要特定格式的输入才能产生满意的结果,在选择的模型中,只有 Llama2 和 CodeLlama 有特定的提示格式。Gemma 和 CodeGemma 没有任何格式可遵循,所以作者使用相同的promot,然后存储格式化的数据以进行微调和测试
微调基本模型
对选定的 LLM(Llama2、Gemma、CodeLlama、CodeGemma)进行微调和训练。
微调过程旨在使模型的参数适应代码漏洞检测任务,同时最大限度地减少过拟合并最大限度地提高泛化能力。使用优化的超参数和正则化技术进行训练
评估 LLM
包括定量和定性的评估,来判断模型的真实场景下代码处理能力
将结果与最先进的 LLM 进行比较
将 GPT-4、PaLM 和 Llama 的性能与 CodeBERT、CodeGPT 和 GPT-2base 等已建立的最先进的 LLM 进行了比较,为了对探索较少的 LLM 的有效性进行基准测试,并确定优势或改进的领域。
- Llama 2: Transformer架构,具备从7B到65B参数的模型,经过微调用于自然语言和代码生成任务。
- CodeLlama: Llama 2的代码专用版本,适合从代码或自然语言生成代码。
- Gemma: Google的轻量级开源模型,主要用于对话生成任务。
- CodeGemma: 针对代码生成任务的模型,支持文本到代码转换。
Part7. experiment
实验设置
实验使用了谷歌的Colab Pro进行模型训练和测试,利用NVIDIA A100 GPU以加速计算。每个模型的微调平均耗时15分钟,测试则需要1.5小时。研究者对每个模型进行了10次试验,以找到最佳参数和提示。
微调 Llama 2 和 Gemma 模型时获得的训练损失如下,Llama 需要比 Gemma 更大的批量大小,因此点数较少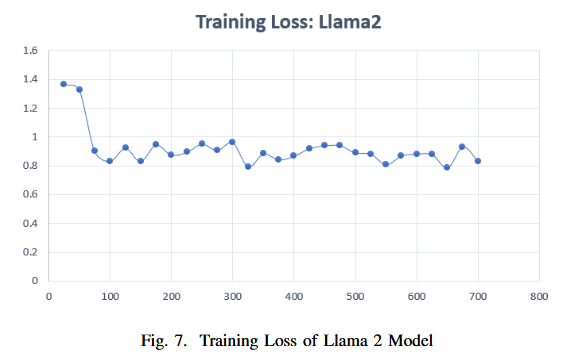
微调和测试 LLM
Llama2 & CodeLlama by Meta::
使用 “text generation ”任务模型和适当的提示工程,选择 Hugging Face 的预训练模型 “llama 2 7b chat hf” 并进行了微调,并使用QloRa技术进行参数高效微调(PEFT),因为它允许以 4 位精度微调模型,从而大大减少了 VRAM 的使用量
Gemma & CodeGemma by Google
使用 ‘instruct’ 变体进行文本生成任务。选择 Hugging Face 的预训练模型 “gemma-1.1-7b-it” 并对其进行了微调。为 CodeGemma 选择了 ‘instruction-following’ 模型变体。选择预训练模型 “google/code-gemma-7b-it” 进行微调。提示符与 Llama 2 几乎相同,同时也使用QloRa技术进行参数高效微调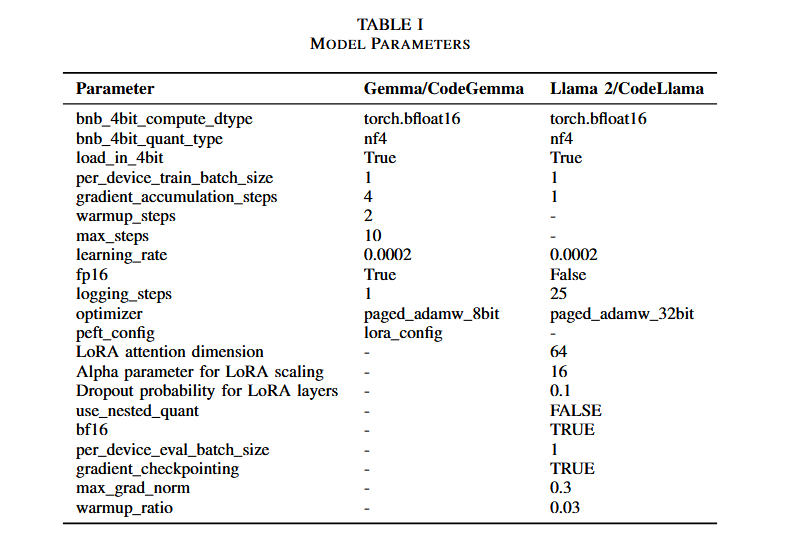
EVALUATION
评估指标: 准确率、精确率、召回率、F1-score 和计算效率。
结果:
- Llama2 的准确率最高,为65%,而CodeGemma 在召回率(87%)和F1-score(58%)方面表现最佳。
- CodeGemma 尽管在准确率上低于Llama2,但在检测到的漏洞数量和分类平衡性上表现更好。
对比传统LLMs如GPT-2 Base、CodeGPT和CodeBERT,新兴模型在精确率和召回率方面表现出了优势。
Result:
RQ1:最近引入的大型语言模型在检测代码漏洞方面有多有效?
研究发现,最新的LLM,如Llama2和CodeLlama,在漏洞检测方面表现良好。Llama2的准确率最高,达到了65%,而CodeLlama稍低,为60%。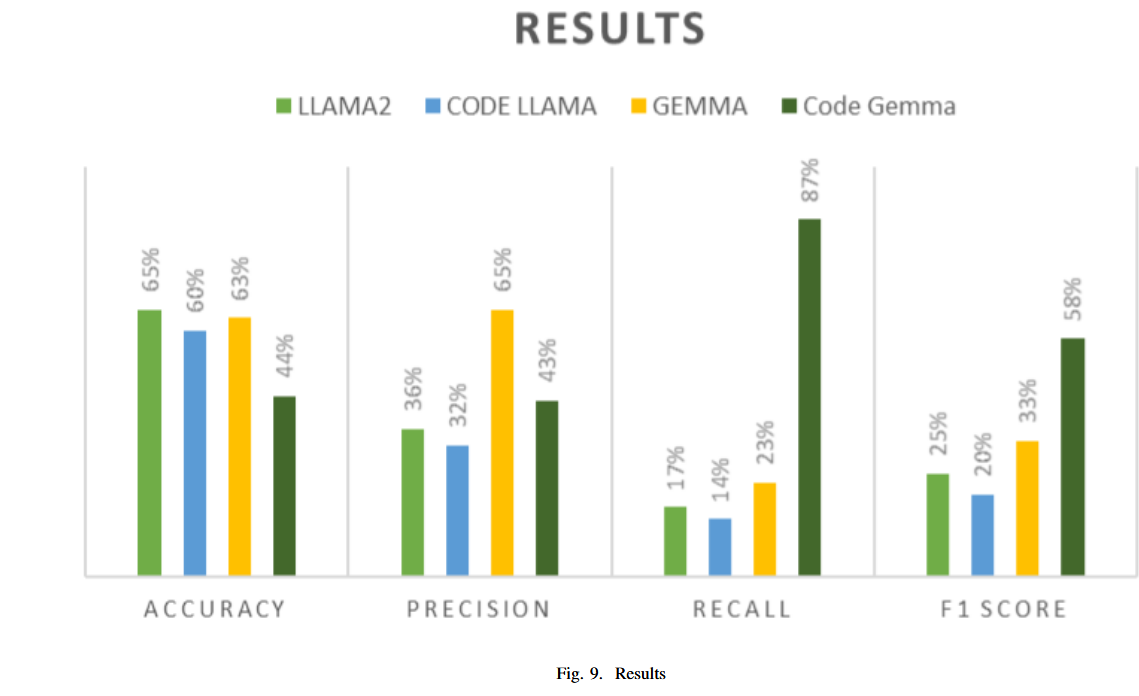
RQ2:基于自然语言的LLM能否优于基于代码的模型?
性能比较表明,自然语言基于的LLM(如Llama2和Gemma)与基于代码的LLM(如CodeLlama和CodeGemma)之间没有显著差异。然而,CodeGemma在召回率(87%)和F1得分(58%)方面表现尤为突出,表明其在识别漏洞方面尤其有效。
RQ3:研究结果与最新的主流模型相比如何?
与已建立的LLM模型相比(如GPT-2和CodeBERT),研究发现尽管传统模型在准确性方面表现更好(例如GPT-2和CodeGPT准确率高达91%),但在召回率和F1得分等其他指标上,新模型(如CodeGemma和Gemma)在检测漏洞方面表现出色。
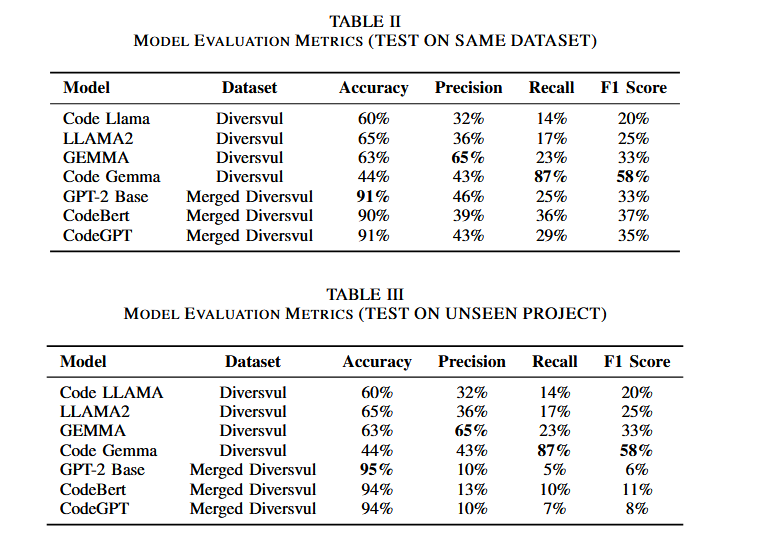
RQ4:新LLM的发现与已有模型相比如何?
尽管LLM表现出色,但仍存在一些局限性和偏差,尤其是在处理特定任务时。研究指出,LLM的性能不能仅通过已知的强指标来评估。每个任务都有独特的挑战和细微差别,可能无法通过模型的能力充分应对。因此,评估LLM在每个任务和领域的表现非常重要,而不是假设其在相关任务中的表现是统一的。
Part8. discussion&future work
尽管LLMs在代码漏洞检测中表现出色,但其在特定任务上的不稳定性仍是一个问题。例如,Llama 2 在某些情况下能正确检测到漏洞并提供解释,但其响应与提示不符,显示出模型在提示一致性方面的局限性。未来的工作可以通过训练更大版本的模型并扩展数据集来提升性能。
总的来说,虽然LLMs表现出令人期待的结果,但其计算资源的需求和在处理大型代码库或实时应用中的可扩展性问题仍需要进一步研究。
在代码漏洞检测领域,CodeGemma表现最佳。尽管Llama2在准确率上最高,达到65%,但CodeGemma在其他重要指标上表现优异,特别是召回率(87%)和F1得分(58%)。这表明CodeGemma在识别易受攻击的代码方面特别有效,尽管它的准确率为44%



