VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
Part1. Title & Source
Title: VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
Authors: Hazim Hanif and Sergio Maffeis
Source: Conference Paper, IJCNN 2022
Part2. Abstract
该论文提出了VulBERTa,一种深度学习方法,用于检测源代码中的安全漏洞。其方法是基于RoBERTa的模型,在真实的开源C/C++项目代码上进行预训练。VulBERTa通过自定义的词元化管道,学习代码的语法和语义表示,并利用这些知识来训练漏洞检测分类器。评估结果显示,VulBERTa在多种数据集(Vuldeepecker、Draper、REVEAL、muVuldeepecker)和基准测试(CodeXGLUE和D2A)中表现优异,超越了现有方法,具有较小的训练数据规模和模型参数数量。
Part3. Introduction
随着每年软件CVEs的提交数量不断增加,软件漏洞检测领域的研究逐渐增多。现有的漏洞检测方法包括静态分析、动态分析和基于机器学习的模型。深度学习技术(如Bidirectional-LSTM和图神经网络GNN)在软件漏洞检测上取得了一定的成果。本文采用Transformer架构的RoBERTa模型进行预训练,目标是学习C/C++代码的深层表示,并用于漏洞检测模型的构建。
作者提出了VulBERTa,一种基于RoBERTa的预训练模型,使用自定义的词元化管道解析C/C++代码,保留代码的基本语法和语义信息,经过预训练后,模型被微调用于漏洞检测任务。同时,作者提出将BPE算法和预定义的代码标记相结合结合的自定义标记化管道,在保持源代码句法结构的同时提供更好的代码编码。
Part4. Conclusion
VulBERTa是一种有效的C/C++代码漏洞检测预训练模型。通过自定义词元化和MLM预训练,该模型在多个数据集上取得了SOTA(state-of-the-art)表现。即使使用较小规模的数据集和模型参数,VulBERTa也展现出优越的漏洞检测性能。未来的工作可能集中于扩展模型规模、优化超参数调优以及检测未知0-day漏洞。
Part5. Related Work
A. 深度学习在漏洞检测中的应用
早期工作(如Vuldeepecker、SySeVR、muVuldeepecker)基于库/API函数调用或图结构信息对漏洞进行检测,使用LSTM、CNN和GNN进行训练。然而,这些方法往往过于依赖手工提取的特征(如代码小部件、控制流图等),且检测范围有限。
B. 源代码的预训练模型
预训练技术在自然语言处理(NLP)中表现优异(如BERT、RoBERTa)。近年来,预训练模型开始应用于编程语言的表示学习。诸如C-BERT和CodeBERT模型通过预训练生成代码的深层表示,但它们的数据规模大,模型参数多。VulBERTa则通过优化词元化技术和减少预训练数据集,实现了更为轻量化的漏洞检测模型。
Part6. Model&Framework
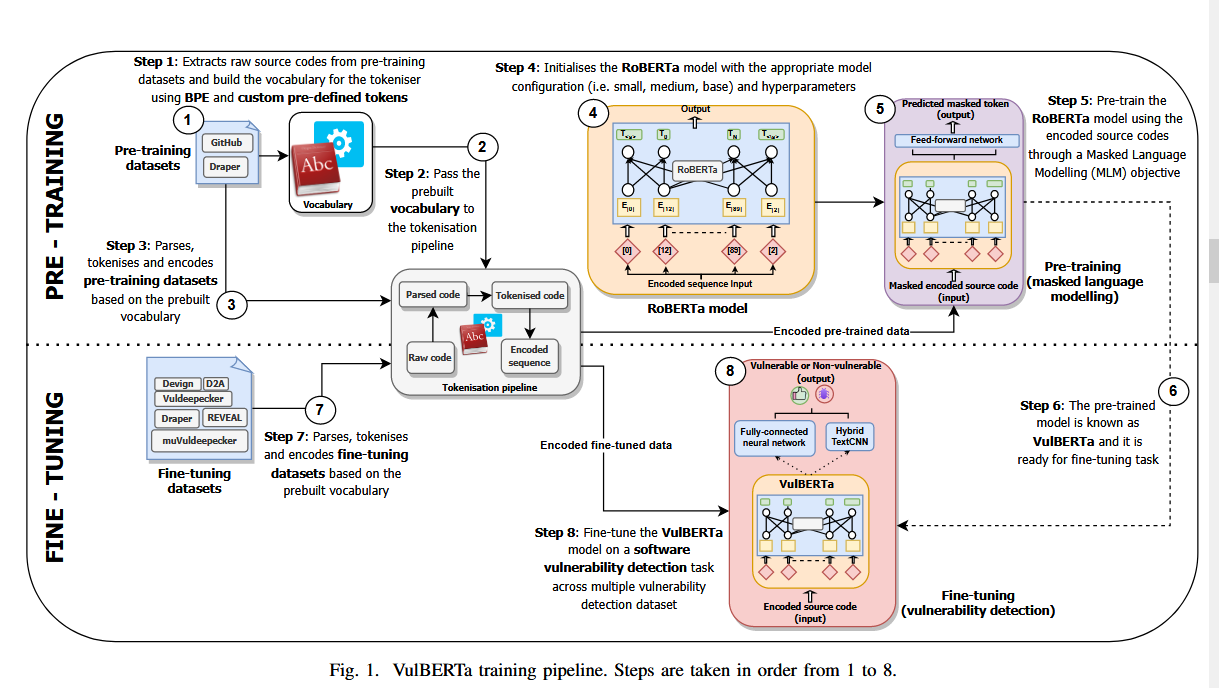
VulBERTa模型由以下三部分组成:
A. 词元化技术
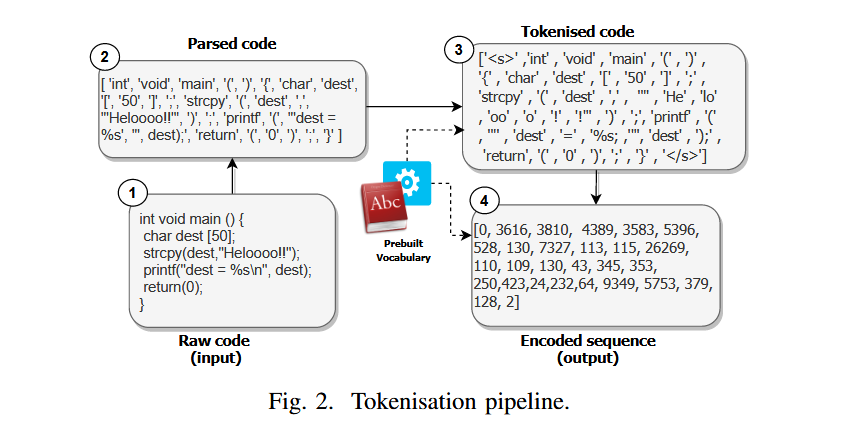
VulBERTa的词元化管道保留了代码的语法结构和部分语义标识符,包括解析、词元化和编码三步。首先,使用Clang解析代码生成代码词元,再通过自定义的BPE算法将词元进一步细分为细粒度的编码单元。BPE算法避免了词汇超出范围的问题,VulBERTa的词汇量设置为50000,并通过预定义的C/C++关键词、标点符号和API调用保留关键语法信息。
Tokeniser
- Parser
使用正则化表达式删除注释,然后使用Clang解析源码
- Tokenisation
Clang 解析器生成的令牌由 BPE 算法进行修改以考虑预定义的tokens,进一步将解析的输入分解为细粒度的令牌以进行编码。
Byte Pair Encoding (BPE):
是一种子词分词化算法,它将一对类似的连续字节替换为数据中未出现的字节。它通过反复合并文本中最常见的字节对,生成新的词元,最终得到一个词汇表。
eg:假设有一个包含以下句子的语料:
low, lowest, newer, wider
Step 1: 初始化字符
首先,将每个单词中的字符看作一个独立的词元:
low→l o wlowest→l o w e s tnewer→n e w e rwider→w i d e r
Step 2: 统计字节对的频率
在语料中查找最频繁的字节对(字符对),例如,假设”l o”是出现最多的对。
Step 3: 合并最频繁的字节对
将频率最高的字节对“l o”合并为一个新的符号“lo”:
lo wlo w e s tn e w e rw i d e r
Step 4: 重复合并过程
继续统计剩余的字节对,找到出现频率最高的对并合并。例如,接下来合并”w e”:
lo wlo w e s tn ew erw i d er
然后合并“er”:
lo wlo w e s tn ew erw i d er
重复此过程,直到达到预设的词汇表大小或合并结束。
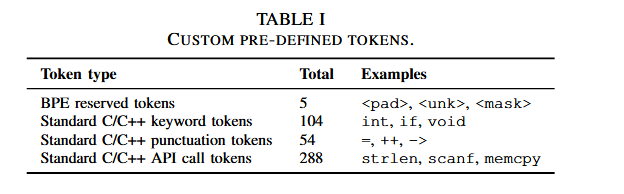
Pre-defined tokens:
是明确包含在词汇表中的标记,因此会将它们排除在子词标记化过程中。通过预定义 C/C++ 关键字、标点符号和标准 API 名称,我们可以在预训练期间保留有关源代码含义的更多信息。示例:
Encoder:
将代码标记转换为张量,使用特殊的 padding token 将较短的序列向右填充
B. 预训练
VulBERTa在GitHub和Draper数据集上进行MLM(Masked Language Modelling)预训练,学习代码的语法和语义表示。模型的嵌入维度设置为768,训练了50万步。
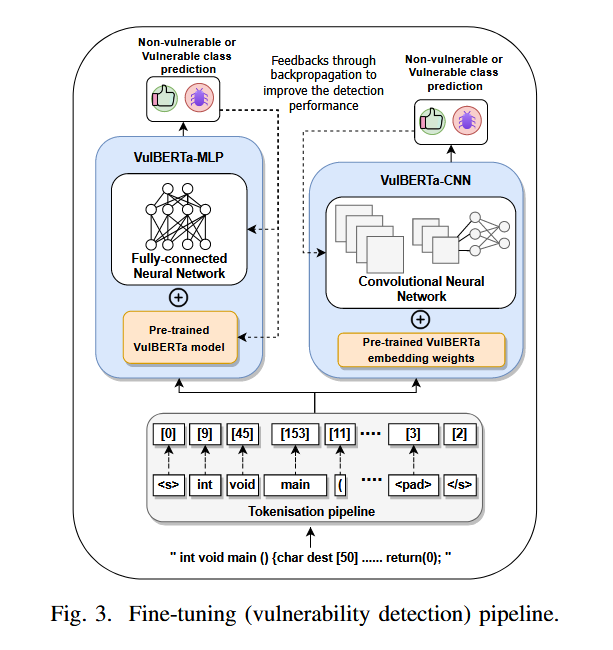
C. 微调
预训练后,VulBERTa被微调用于漏洞检测任务。本文提出了两种微调模型:VulBERTa-MLP和VulBERTa-CNN。VulBERTa-MLP使用全连接层进行二分类或多分类任务,VulBERTa-CNN则使用TextCNN架构进行漏洞检测。在微调过程中重用来自 VulBERTa 的预训练权重,并继续训练几个 epoch
VulBERTa-MLP:
根据微调数据集是二进制还是多类分类数据集,实现一个具有 768 个神经元和一个输出层 2 或 41 个神经元的全连接层。
VulBERTa-CNN:
提取了预训练的 VulBERTa 模型的嵌入权重,并将其用作混合文本 CNN 的嵌入权重 [30]。TextCNN 架构由三个一维 CNN 组成,每个 CNN 都有自己的最大池化层。输出是连接和平展的,然后馈送到两个全连接层(256 个和 128 个神经元),其中一个输出层用于分类。
Part7. Experiment
Dataset
- 预训练数据集
使用 GitHub 和 Draper 数据集上的掩码语言建模 (MLM) 任务。
从github提取源代码的函数并用api进行编译,然后使用Joern从每个下载的文件中有效地提取各个函数
Draper范围从高度记录的生产代码到综合测试样本。
- 微调数据集
Vuldeepecker:来自国家漏洞数据库 (NVD)的真实样本和来自软件保障参考数据集 (SARD)项目的合成样本组成
Draper:与上述相同,但是为了进行微调,增加了(二进制)标签
REVEAL:是引入的真实世界软件漏洞检测数据集,该数据集是一个二进制检测数据集,由两个开源项目(Linux Debian 内核和 Chromium)的源代码组成
muVuldeepecker (MVD):多类漏洞检测数据集。它与 Vuldeepecker 数据集非常相似,因为该数据集也来自 NVD 和 SARD。但是,主要区别在于此数据集由代码小工具组成,而不是通常的函数级源代码。
Devign:该数据集由来自两个流行的开源软件项目 QEMU 和 FFmpeg 的函数级 C/C++ 源代码组成
D2A:该数据集由多个开源软件项目组成,如 FFmpeg、httpd、Libav、LibTIFF、Nginx 和 OpenSSL。它是使用差分分析技术创建的,用于标记静态分析器报告的问题
Baseline:
Baseline-BiLSTM:该技术是 LSTM 的一种变体,它实现了两层双向 LSTM [36] 和几个全连接层,以从源代码序列中学习以进行漏洞检测。双向 LSTM 同时学习码序的正向和反向关系。(ii) Baseline-TextCNN:这是 CNN [30] 的变体,其中输入数据是自然语言文本而不是图像。在这种情况下,我们使用源代码作为输入数据并将其馈送到 CNN 中。该技术使用池化部署三个卷积层,并将它们连接成一个层,然后将结果传递到几个全连接层
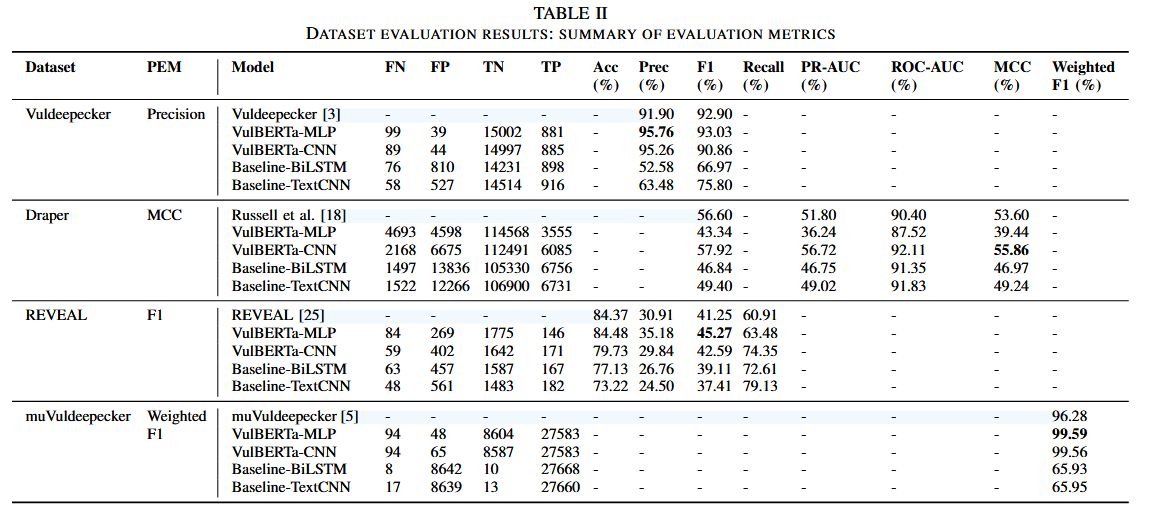
实验使用了多个漏洞检测数据集,VulBERTa在各个数据集上的表现如下:
- Vuldeepecker:VulBERTa-MLP实现了93.03%的F1分数,超越了原始模型的92.9%。
- Draper:VulBERTa-CNN的MCC得分为55.86%,比原有模型提升了2.26%。
- REVEAL:VulBERTa-MLP的F1分数为45.27%,显著高于41.25%。
- muVuldeepecker:在多分类任务中,VulBERTa-MLP的加权F1分数达到了99.59%。
VulBERTa还在CodeXGLUE和D2A两个基准测试中取得了优秀成绩,尤其是在使用较少的训练数据和较小的模型参数的情况下。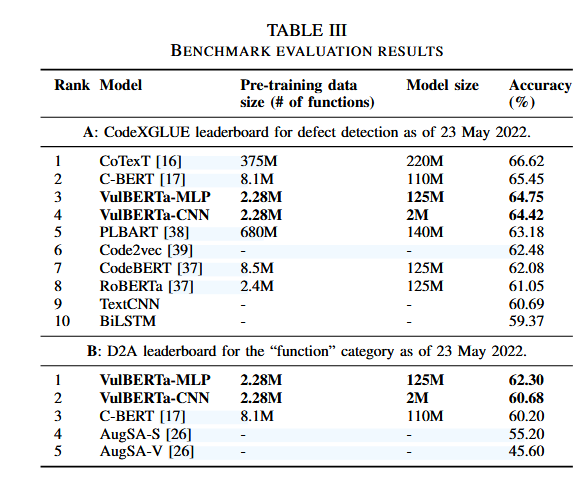
Part8. Discussion & Future Work
讨论
VulBERTa-MLP和VulBERTa-CNN在多数据集上表现接近,均展示了良好的漏洞检测能力,特别是在小规模预训练数据和模型参数下实现了SOTA性能。作者认为词元化技术在保持代码语法和语义信息上起到了关键作用,使得这些信息能够被简单的神经网络架构使用。
未来工作
未来可以在更大规模的数据集和模型上进一步优化,包括超参数调优。同时,VulBERTa在现实世界中的0-day漏洞检测尚未系统性地进行验证,这是未来工作的一个重要方向。



