SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities
Part 1. Title & Source
Title: SySeVR: A Framework for Using Deep Learning to Detect Software Vulnerabilities
Source: IEEE Transactions on Dependable and Secure Computing
Part 2. Abstract
该论文提出了一个名为SySeVR的系统化框架,用于通过深度学习检测C/C++程序中的软件漏洞。SySeVR框架旨在生成包含漏洞语法和语义信息的程序表示,并通过四种软件产品的实验,验证了其在检测未报告漏洞方面的有效性。该框架成功检测了15个新的漏洞,其中7个被报告给厂商,8个在新版本中被“悄悄”修复。
Part 3. Introduction
软件漏洞是网络攻击的主要原因之一,尽管研究界和工业界都在努力提高软件质量,但每年仍然有大量的漏洞被报告。现有的基于代码相似性和模式的漏洞检测方法存在高误报率或对人工特征定义的依赖,而深度学习的引入能够减少这种依赖。然而,深度学习的应用面临数据表示的挑战,因为软件程序不像图像等领域具备天然的向量表示。为了解决这一问题,作者提出了SySeVR框架,通过语法和语义信息的综合表示来检测漏洞,并通过数据依赖和控制依赖的语义扩展提高检测效果。SySeVR框架提出了两种新的概念:基于语法的漏洞候选者 (SyVC) 和基于语义的漏洞候选者 (SeVC) 的概念。SyVCs基于程序的语法特征提取,如函数调用、指针使用等,而SeVCs通过程序切片技术,结合数据依赖和控制依赖,从而捕捉更多与漏洞相关的上下文信息。每个SeVC都会被转换为向量表示,以输入到深度神经网络进行训练和检测。主要使用的神经网络模型为双向GRU(BGRU),并通过控制依赖和数据依赖的扩展优化了漏洞检测的准确性。
Part 4. Conclusion
SySeVR框架通过结合语法、语义信息和向量表示,有效提高了漏洞检测的准确率。实验表明,使用BGRU的深度神经网络在四种开源软件产品中检测到多个未被报告的漏洞。未来的工作将致力于进一步改进漏洞表示和检测方法,同时优化模型以应对更多类型的漏洞和不同编程语言。
Part 5. Related Work
现有的漏洞检测方法包括基于代码相似性和模式的方法,但这些方法存在一定的局限性。代码相似性方法适用于代码克隆引发的漏洞,但对于其它类型的漏洞检测效果较差。模式匹配方法则依赖专家手动定义漏洞特征,这使得其容易出错且费时费力。此外,作者提到了先前的VulDeePecker系统,这是第一个基于深度学习的漏洞检测系统,但其仅支持基于函数调用的漏洞检测,忽略了语义信息及其它依赖类型。
Part 6. Model&Framework
作者的思路是将一个程序划分为更小的代码段,并将这些代码对应于图像领域的region proposals来展示漏洞的语法和语义特征
定义SyVC
程序的组成:
程序 (Program):一个程序是由若干个函数组成的集合,表示为$P={f_1,f_2,…,f_\eta}$,其中每个函数$f_i$都包含一系列有序的语句。
函数 (Function):一个函数$f_i$是一组有序语句的集合,表示为$f_i={s_{i,1},s_{i,2},…,s_{i,m_i}}$,其中每条语句$s_{i,j}$可能包含一个或多个标记。
语句(Statement):语句$s_{i,j}$是一组有序标记(tokens)的集合,表示为$s_{i,j}={t_{i,j,1},t_{i,j,2},…,t_{i,j,w_{i,j}}}$。每个标记可以是标识符(identifier)、操作符 (operator)、常量(constant)或关键字(keyword),这些可以通过词法分析提取出来。
SyVC的正式定义如下:
代码元素(Code Element):代码元素是一个或多个连续的标记组成的片段,表示为$e_{i,j,z}=(t_{i,j,u},…,t_{i,j,v})$ ,其中$1\leq u\leq v\leq w_i,j$。
SyVC: 如果一个代码元素$e_{i,j,z}$符合某个漏洞语法特征$h_k$ ,那么这个代码元素就被称为SyVC。漏洞语法特征的集合用$H={h_1,h_2,…,h_\beta}$表示,其中$h_k$代表一种特定的漏洞语法特征。
算法1:从程序中提取SyVC

生成AST:
抽象语法树(AST)是对程序结构的分层表示,AST的节点表示程序中的不同语法元素。每个函数会被转换为AST,SySeVR利用AST对函数进行遍历,以识别潜在的漏洞代码。遍历AST中的代码元素:
在AST中,每个节点表示一个代码元素,这些代码元素可能是变量、操作符、数组、指针或函数调用等。SySeVR遍历AST中的每个代码元素,并将其与已定义的漏洞语法特征进行匹配。匹配漏洞语法特征:
SySeVR定义了一组漏洞语法特征(如函数调用、数组操作、指针使用、算术表达式等),这些特征可以从AST中直接识别。例如:- 如果某个代码元素是函数调用,并且该函数是已知的易受攻击的API(如
strcpy),那么这个代码元素会被标记为SyVC。 - 如果某个变量是指针类型(例如包含符号
*),并且指针操作可能导致内存漏洞,那么这个代码元素也会被标记为SyVC。
- 如果某个代码元素是函数调用,并且该函数是已知的易受攻击的API(如
SyVC→SeVC
目的是通过程序切片技术,捕捉与SyVC相关的上下文语义信息,使得漏洞检测模型能够更全面地理解代码中的潜在漏洞。这个转换过程主要依赖于数据依赖(Data Dependency)和控制依赖(Control Dependency)
过程如下:
1.SyVC的提取
SyVC是基于代码的语法特征提取的,它们是潜在的漏洞候选。SyVC可以是函数调用、指针使用、数组操作或算术表达式等。每个SyVC代表代码中的一个可能与漏洞相关的语法结构,但单独的语法信息不足以精确地检测漏洞
2. 数据依赖与控制依赖
程序中的语义信息通过数据依赖和控制依赖进行捕捉。数据依赖指的是一个代码元素(如变量)如何影响另一个代码元素,控制依赖则指代码块间的执行顺序如何相互影响。通过分析这些依赖关系,系统可以找到与SyVC相关的上下文代码。
- 数据依赖:如果一个变量的值在不同代码语句中被使用(例如赋值和使用),那么这些语句之间就存在数据依赖。
- 控制依赖:如果某条语句的执行取决于其他语句的条件(如if-else或循环条件),则这些语句之间存在控制依赖。
3.程序切片技术(Program Slicing)
SyVC→SeVC转换的核心技术是程序切片(Program Slicing)。程序切片是一种通过分析程序的依赖关系,提取与某个代码元素相关的所有语句的技术。SySeVR通过两种切片方式生成SeVC:
前向切片:从SyVC开始,找出那些受到SyVC影响的代码语句。
后向切片:找出那些影响了SyVC的代码语句。
这两种切片方法结合起来,可以帮助识别出与SyVC相关的语义信息,形成SeVC
4.SeVC的生成
经过前向和后向切片后,系统将所有与SyVC相关的代码片段组合起来,生成SeVC。SeVC不仅包含SyVC本身,还包含与其存在语义关系的其他代码语句。这一过程通过控制和数据依赖的关系,确保SeVC能够准确捕捉漏洞的上下文。
例如,如果SyVC是一个指针操作,那么SeVC可能包含所有与该指针相关的内存分配、解引用和使用操作。这些相关代码块共同构成了SeVC,并被转换为向量表示,以供深度学习模型进行训练和检测
定义 SeVC
SeVCs(语义漏洞候选)是从SyVCs(语法漏洞候选)的基础上进一步扩展语义信息的关键步骤。通过将程序切片技术应用于SyVC,系统能够捕捉与漏洞相关的上下文语句,生成更具语义关联的漏洞候选(SeVC)
给定一个程序$P=\left{f_1,f_2,…,f_\eta\right}$ 和一个SyVC $e_{i,j,z}$ (在函数$f_i$ 的语句$s_i,j$中的某个代码元素),与这个SyVC相关的SeVC $\delta_{i,j,z}$ 是程序$P$中的一个有序语句子集,表示为:
$\delta_{i,j,z}={s_{a_1,b_1},s_{a_2,b_2},…,s_{a_{v_{i,j,z}},b_{v_{i,j,z}}}}$
其中,$s_{a_p,b_q}$ 是通过数据依赖或控制依赖与SyVC $e_{i,j,z}$ 相关的语句。换句话说,SeVC是一个程序切片,它包含了与SyVC相关的所有语句,基于这些语句的语义关系(例如变量间的依赖或控制流的依赖)。
计算 SeVC
过程:
- 生成PDG(2-4行)
- 生成程序切片(6-9行)
- 转换为Sevc(10-19行)

10-12:行对于每个出现在程序切片中的语句,根据它们在原函数中的顺序,将它们依次添加到SeVC $\delta_{i,j,z}$ 中。SeVC包含与SyVC相关的所有语句,这些语句共同形成一个上下文,以捕捉漏洞的语义信息。
13-19行:当涉及跨函数调用时,算法根据调用关系决定语句的顺序
如果函数$f_i$调用了函数$f_{ap}$,则将$f_i$中的语句排在$f_{ap}$中的语句之前。
如果$f_{ap}$调用了$f_i$,则反过来,$f_{ap}$中的语句排在$f_i$中的语句之前。
将 SeVC 编码为向量

首先对每个$SeVC \delta_{i,j,z}$ 进行预处理(2-6)
- 移除非ASCII字符和注释:这一步删除代码中的注释和特殊字符,使得代码更简洁。
- 符号化变量和函数名:将用户定义的变量名和函数名映射为通用的符号。例如,将变量名
buffer映射为V1,将函数名strcpy映射为F1。这样做的目的是去除代码的具体实现细节,保留逻辑结构。
对SeVC中的符号进行向量化(7-13)
符号分割:将SeVC分解为一系列符号(例如变量、运算符、常量等)。
符号向量化:将每个符号$\alpha$转换为一个固定长度的向量$v(\alpha)$,例如每个符号可以被表示为30维向量。
连接符号向量:将这些符号的向量依次连接起来,生成表示SeVC的向量$R_{i,j,z}$。
标准化向量长度(填充或截断)(14-22)
填充:如果向量长度小于 θ,则在向量末尾填充零,直到达到 θ。
截断:如果向量长度超过 θ,则根据SyVC的位置截断符号,以确保SyVC在向量的中心。
- 如果SyVC之前的部分小于 θ/2,则截断右侧多余部分。
- 如果SyVC之后的部分小于 θ/2,则截断左侧多余部分。
- 否则,保留SyVC两侧的符号,使最终向量的总长度等于 θ
Part 7. Experiment
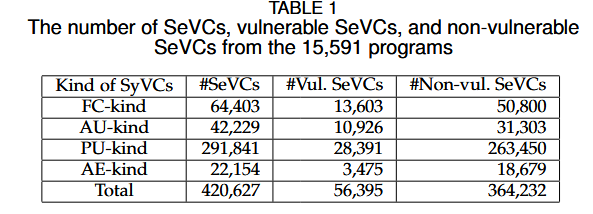
实验使用了从NVD和SARD中收集的15,591个C/C++程序,并包含126种不同类型的漏洞。研究表明,SySeVR框架中的BGRU模型在检测漏洞时优于单向RNN和传统的卷积神经网络(CNN)。通过对比,BGRU模型的假阳性率为1.7%,假阴性率为19.0%,相比VulDeePecker系统的效果有显著提升。此外,实验中还检测到15个NVD未报告的漏洞。
实验过程:
- Extracting SyVCs
使用了商业工具checkmarx,并最后进行手动检查,漏洞种类包括:Library/API Function Call、Array Usage、Pointer Usage、Arithmetic Expression并且互相之间都有重合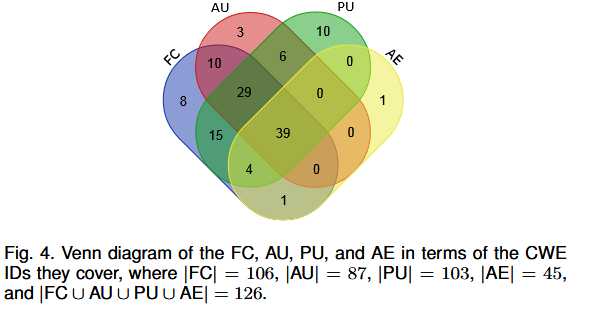
为了使用算法 1 提取 SyVC,我们需要确定程序 P 中函数 fi 的抽象语法树 Ti 上的代码元素$e_{i,j,z}$ 是否与漏洞语法特征匹配,下面的方法可以自动检测代码片段$e_{i,j,z}$ 是否与语法特征匹配
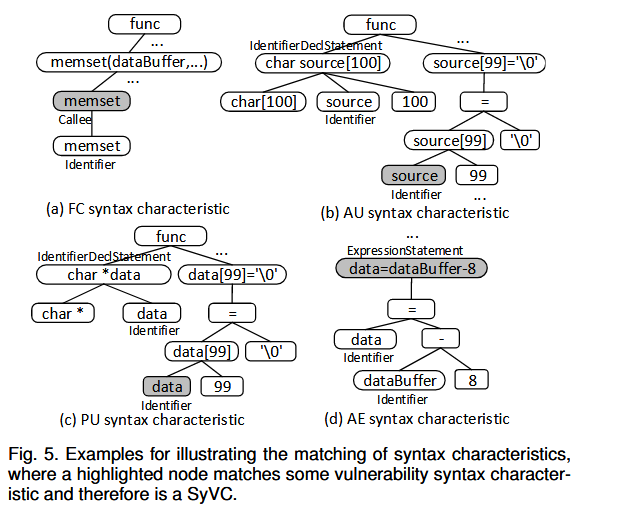
- Transforming SyVCs to SeVCs
- Encoding SeVCs into Vector Representation
采用word2vec将 SeVC 的符号编码为固定长度的向量
- Generating Ground-truth Labels of SeVCs
生成真实标签的目的是为每个SeVC分配一个标记,表示该SeVC是否包含漏洞。这个过程确保了模型可以通过有监督的学习来区分有漏洞和无漏洞的代码片段
步骤如下:
匹配SeVC与漏洞数据
- 对于每个SeVC,系统会检查该SeVC所在的程序或代码片段是否与数据集中标识的漏洞程序相匹配。
- 如果某个SeVC与包含漏洞的程序代码片段相对应,则该SeVC会被标记为正标签(vulnerable, 1)。
- 如果某个SeVC来自无漏洞的代码片段,或者对应代码已经修复,则该SeVC会被标记为负标签(non-vulnerable, 0)
标签的细粒度控制
- 正样本(vulnerable):这些SeVC来自包含实际漏洞的代码。例如,某个指针操作或数组访问可能导致缓冲区溢出,系统会为这些代码片段生成正标签。
- 负样本(non-vulnerable):这些SeVC则来自未发现漏洞的代码,或修复后的代码。这些代码已经通过修复过程消除了已知的安全隐患,或者本身从未存在漏洞
RQ1:检测多种类型漏洞的能力
为了验证SySeVR能否检测多种类型的漏洞,作者分别训练了基于BLSTM模型的SySeVR,并检测了四种主要的漏洞类型:
- 函数调用(FC)
- 数组使用(AU)
- 指针使用(PU)
- 算术表达式(AE)
实验使用了从训练集中随机选出的30,000个SeVC进行训练,7,500个SeVC用于测试。作者还对比了SySeVR和现有的VulDeePecker系统的性能,后者仅检测函数调用(FC)相关的漏洞。
结果:SySeVR成功检测了多种类型的漏洞,相比VulDeePecker,在检测函数调用相关漏洞时,F1值提高了3.4%,假阳性率(FPR)降低了5.0%。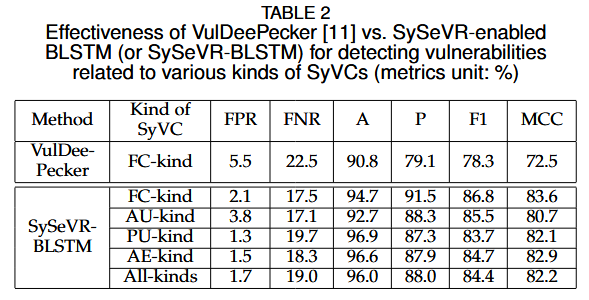
RQ2:不同神经网络模型的性能比较
为验证SySeVR在多种神经网络架构下的性能,作者测试了以下八种模型:
- Logistic Regression (LR)
- Multi-Layer Perceptron (MLP)
- Deep Belief Network (DBN)
- Convolutional Neural Network (CNN)
- 四种不同的RNN模型:LSTM、GRU、BLSTM、BGRU
每种模型都通过交叉验证(5折交叉验证)进行训练,作者对比了每种模型的假阳性率、假阴性率、准确率、F1值等指标。
结果:BGRU模型表现最佳,F1值为85.8%,MCC为83.7%。Bidirectional RNN(双向RNN)在捕捉代码前后依赖关系时比单向RNN具有更好的性能,CNN模型次之,而DBN和浅层模型(LR和MLP)的效果较差。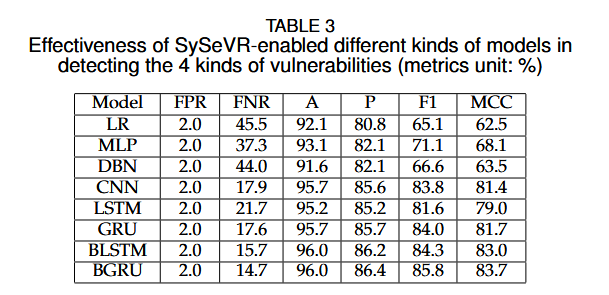
使用分布式表示(例如 word2vec)来捕获上下文信息对于 SySeVR 非常重要。特别是,以令牌频率为中心的表示是不够的
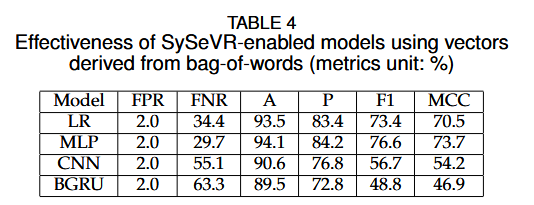
RQ3:控制依赖的影响
为了评估控制依赖在漏洞检测中的影响,作者比较了仅使用数据依赖的信息和同时使用数据依赖与控制依赖的信息的检测效果。
结果:引入控制依赖能够显著提升检测效果,假阴性率(FNR)平均降低了30.4%。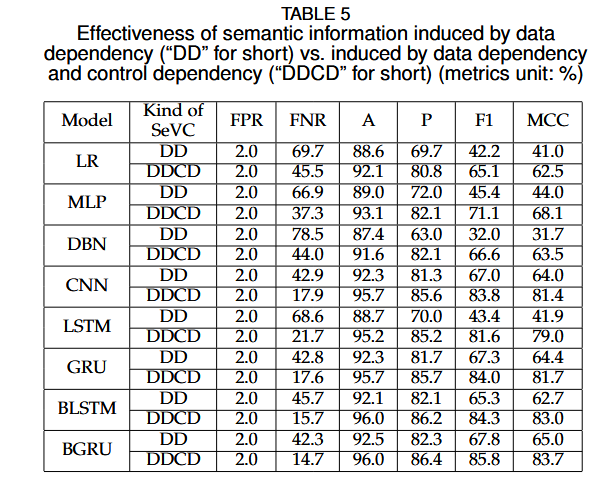
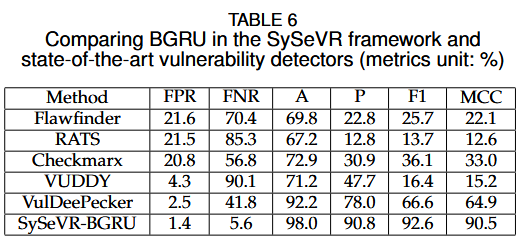
RQ4:与最先进方法的对比
作者将SySeVR与VulDeePecker等现有的漏洞检测方法进行了比较,后者是第一个基于深度学习的漏洞检测系统,主要检测与函数调用相关的漏洞。
结果:SySeVR在多个漏洞类型的检测中均优于VulDeePecker,尤其是在捕捉更多语义信息(例如控制依赖)的情况下,SySeVR的表现更为出色。
Part 8. Discussion & Future Work
SySeVR框架展示了深度学习在软件漏洞检测中的强大潜力,特别是当它能够结合语法和语义信息时。未来工作将专注于进一步改进SyVC和SeVC的提取方法,以及探索该框架在不同编程语言和更多漏洞类型中的适应性。此外,研究者计划优化框架的性能,以处理更大规模的代码库和更复杂的漏洞类型。



