A Search-Based Testing Framework for Deep Neural Networks of Source Code Embedding
Part 1. Title & Source
Title: A Search-Based Testing Framework for Deep Neural Networks of Source Code Embedding
Published: 2021 ICST
Part 2. Abstract
这篇文章提出了一个基于搜索的测试框架,用于源代码嵌入的深度神经网络 (DNN) 及其下游处理任务(如代码搜索)的对抗性测试。通过代码重构工具生成语义等效的变体来生成新的测试输入,并使用DNN突变测试来指导测试方向。通过在多个基于最先进代码嵌入方法(如Code2vec、Code2seq和CodeBERT)上的大规模评估,结果显示生成的对抗样本使DNN的性能下降了5.41%到9.58%。通过使用生成的对抗样本进行重新训练,DNN的鲁棒性平均提升了23.05%。
Part 3. Introduction
近年来,DNN广泛应用于医疗影像、自动驾驶、自然语言处理等领域。越来越多的DNN也被应用于软件工程中的源代码处理任务,如代码搜索、注释生成和程序修复。源代码嵌入是这些任务的核心步骤,目标是将代码片段编码为向量表示。然而,尽管代码嵌入模型的准确性被广泛研究,其鲁棒性仍未受到足够重视。
在源代码上下文中,简单的代码改动(如插入日志打印语句)不应改变DNN模型的推理结果,但非鲁棒的DNN可能会对此产生不同的预测结果。本文的目标是通过(1)提出一个基于搜索的测试框架,生成源代码处理任务中的对抗性样本,以及(2)通过重新训练提高模型的鲁棒性。
本文的贡献包括:
- 提出一个基于搜索的测试框架用于源代码嵌入模型的对抗性鲁棒性测试。
- 通过对抗样本重新训练模型以提高其鲁棒性。
- 对多个最先进的代码嵌入模型进行了大规模实证评估。
Part 4. Conclusion
本文提出了一个基于搜索的测试框架,用于评估代码嵌入模型的鲁棒性。通过使用语义保持的代码重构操作生成对抗性样本,本文展示了这些模型在对抗样本上的性能下降。同时,通过对抗样本重新训练,模型的鲁棒性得到了显著提升,表明该框架可以有效地增强代码嵌入模型的鲁棒性。此外,本文的实验结果也表明,对抗性训练在常规测试数据上的负面影响较小。
未来工作包括:
- 扩展至更多编程语言和任务。
- 探索不同的代码生成策略,以提高生成对抗样本的效率和多样性。
Part 5. Related Work
DNN Testing
Neuron Coverage (NC): 这是最早针对DNN提出的覆盖标准,衡量给定测试输入激活的神经元数量与总神经元数量的比例。其后续研究提出了更多基于神经元的结构覆盖标准,例如:
- DeepGauge: 扩展了神经元覆盖的粒度,通过不同层次的神经元激活进行评估。
- DeepConcolic、DeepCT: 这些方法结合符号执行等技术,进一步提高测试的细致程度。
Mutation Testing
突变测试是一种白盒测试方法,通过对程序进行小幅度修改(即”突变”),分析测试用例能否检测到这些修改引发的行为变化。突变分数用于评估测试用例的质量。
在DNN的突变测试中,突变操作主要是对DNN的决策边界进行小幅扰动,以检测模型的鲁棒性。例如:
- DeepMutation: 通过在模型源代码或模型层面进行突变,模拟DNN的微小决策变化,评估模型的一致性。
$MutationScore(T^{\prime},M^{\prime})=\frac{\Sigma_{m^{\prime}\in M^{\prime}}|KilledClasses(T^{\prime},m^{\prime})|}{|M^{\prime}|\times|C^{\prime}|}$
$T^{\prime}$ 是测试数据集。
$M^{\prime}$ 是突变模型集合。
$KilledClasses(T^{\prime},m^{\prime})$ 表示测试数据集$T^{\prime}$ 杀死的模型$m^{\prime}$ 的类数,也就是测试数据导致的
突变模型输出与原始模型不一致的类数。
$|M^{\prime}|$ 是突变模型的总数量。
$|C^{\prime}|$ 是分类任务中的类别总数。
$LCR(x)=\frac{|{f_i\in F|f_i(x)\neq f(x)}|}{|F|}(2)$
$x$ 是输入样本。
$f$ 是原始 DNN 模型。
$F$ 是突变模型的集合 (即多个经过突变的模型)。
$f(x)$ 是原始模型$f$对输入$x$ 的预测标签。
$f_i(x)$ 是突变模型$f_i$对输入$x$ 的预测标签。
Code Embedding
- Code2vec
Code2vec提出了一个神经模型,用于将代码片段编码为连续分布的向量。在方法名预测中,Code2vec通过分析代码的抽象语法树 (AST) 路径来捕捉代码的语义信息。Code2vec 能够捕捉代码中的语义信息,而不仅仅是语法特征。通过对 AST 路径的关注,它可以理解代码的结构和逻辑
- AST路径表示: Code2vec 模型的核心是通过抽象语法树(AST)提取代码片段中的路径。AST路径是从一个终端节点到另一个终端节点的路径,途经的非终端节点是两者的公共祖先。
- 路径上下文 path-context: 通过将源节点、目标节点以及路径信息编码为向量表示,Code2vec 为每条路径生成一个上下文向量,称为路径上下文 path-context。
- 注意力机制: Code2vec 使用注意力机制来对不同的路径上下文进行打分,并生成一个综合表示的代码向量。这个向量代表代码片段的整体语义,最终用于下游任务(如方法名预测)
- Code2seq
Code2seq是一种基于编码器-解码器架构的神经网络模型,专门用于将代码片段转换为序列表示。它也使用抽象语法树 (AST) 路径表示代码,但它的输出是一个序列,而非单一向量,通常用于方法名生成任务
- AST路径编码: Code2seq 将代码片段表示为一组 AST 路径。每条路径从 AST 中的一个节点(如变量或操作符)到另一个节点,并通过该路径来捕捉代码的结构信息。
- 编码器-解码器架构: 该模型采用了双向LSTM作为编码器,逐节点地编码 AST 路径。解码器则基于注意力机制,逐步生成目标序列(如方法名)。
- 序列生成: 与 Code2vec 不同的是,Code2seq 生成的是序列标签(如方法名的子词序列),而不是一个单一标签。这使得它更适合生成长度较长的输出,如代码注释或方法名
- CodeBERT
CodeBERT 是一种双模态(bi-modal)的预训练模型,旨在为编程语言(PL)和自然语言(NL)提供通用的表示。它是基于BERT架构,使用Transformer来学习代码和自然语言之间的语义关系,主要用于支持软件工程中的各种下游任务,如代码搜索、代码文档生成和代码翻译
双模态预训练: CodeBERT 同时在自然语言和编程语言数据上进行预训练,学习二者的通用表示。模型的设计目标是能够理解编程语言(如Python、Java)中的代码,并将其与自然语言(如代码文档或注释)相关联。
预训练任务: CodeBERT 在两个主要任务上进行预训练:
- Masked Language Modeling (MLM): 这与BERT的预训练方式类似,随机掩盖代码或文本中的部分标记,并让模型预测这些掩盖的标记。
- Replaced Token Detection (RTD): 为了捕捉更细致的表示,CodeBERT 还引入了替换标记检测任务,要求模型区分哪些标记是原始的,哪些是经过替换的
三者对比
- 输入和任务类型: CodeBERT 处理的是代码和自然语言的结合任务,如代码搜索、代码注释生成等。相比之下,Code2vec 和 Code2seq 主要处理代码片段的编码,通常用于生成方法名或预测代码结构。
- 模型架构: CodeBERT 基于 Transformer(BERT 架构),而 Code2vec 和 Code2seq 则基于AST路径表示和LSTM。
- 应用范围: CodeBERT 的应用范围更广,不仅限于方法名预测或代码片段生成,还包括自然语言和代码之间的多种任务。
Code Adversarial Models
- 1-Time Mutation
1-Time Mutation 方法是一种简单的随机重构方法。过程:首先分析源代码来提取所有的函数片段,然后随机从预定义的 refactoring 运算符池中选取一个refactor/mutator 进行 mutation。
原片段
1-Time Mutation之后

- k-Time Mutation
跟一次突变相似,只不过是重复k次。
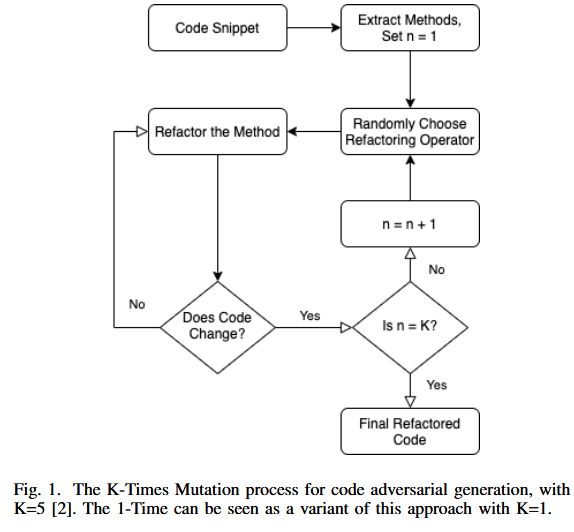
Part 6. Model&Methodology
A:Refactoring as the Test Generation Basis
作者采用重构运算符为源代码生成对抗性样本。并总结了在Java中使用过的方法,包括:
- 局部变量重命名:使用同义词重命名变量的名称(例如,LIST 和 ARRAY、INSERT 和 ADD、FIND 和 SEARCH 等)。
- 参数重命名:使用同义词重命名参数的名称
- 方法名称重命名:使用同义词重命名方法的名称。
- API 重命名:使用局部变量的同义词重命名 API 的名称。API 参数确定要对资源执行的操作类型。每个参数都有一个名称、值类型和可选描述。重命名 API 可以创建具有类似功能的重构代码
- Local Variable Adding:将局部变量添加到代码中。
- Argument Adding:向代码中添加参数。
- Add Print:将 print 添加到代码的随机行。
- For Loop Enhance:将 for 循环替换为 while 循环,反之亦然。
- IF Loop Enhance:将 IF 条件替换为等效逻辑。
- Return Optimal (最优返回) :尽可能更改返回变量
B:Guided Mutation: A Search-based Testing Framework
GM(Guided Mutation)采用进化策略,并遵循与 GA 相同的工作流程,但只对输入群体应用突变而不应用交叉操作。原因是使用 crossover 更改代码片段可能会导致很多错误代码片段。
GM算法中采用精英主义,即将一小部分适者保持不变的复制给下一代。
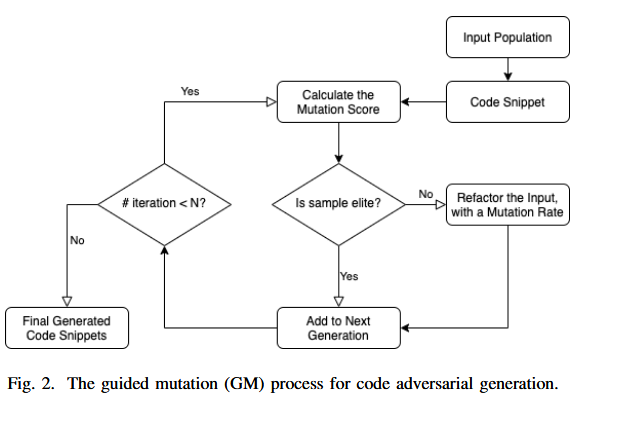
算法步骤:
- 计算当前代码片段群的 mutation 分数
变异分数是衡量代码片段在不同变异后的版本之间输出是否一致的一个指标,GM 使用 DeepMutation++ 框架来计算变异分数。
给定一个输入代码片段 t、一个深度神经网络 m 及其变异体 m',如果在 t 上 m(t) 与 m'(t) 的输出不一致,则 t 被认为“杀死”了变异体 m'。
$MS(t,m,M)=\frac{|{m’|m’\in M\land m(t)\neq m’(t)}|}{|M|}$
M 是所有变异体的集合,MS 是变异分数。
- 根据最高突变分数选择精英候选基因,并将其复制到下一代群体中
在进化算法中,精英策略(Elitism)是为了确保最佳的候选项能够直接进入下一代。这种策略防止在演化过程中丢失之前找到的好解。具体来说,GM 算法在每一代中选择变异分数最高的代码片段作为精英候选项,将它们直接复制到下一代的种群中
- 以指定的突变率改变剩余的候选者。
对于剩余的代码片段,GM 通过变异操作来生成新的代码。每个代码片段都会被应用一个变异操作,这些操作的选择是随机的。变异操作包括:
- 局部变量重命名:将变量名称替换为同义词(例如,将
LIST改为ARRAY)。 - 参数添加:为代码方法添加新的参数。
- 循环增强:将
for循环替换为while循环,或反之亦然。 - 打印语句添加:在代码中添加随机的打印语句。
- 从第一步开始重复,直到满足停止标准(例如,达到指定的迭代次数)
GM 算法通过多次迭代,不断生成新的对抗样本,直到满足某个停止条件,例如达到特定的迭代次数或发现了一定数量的对抗样本。每次迭代都涉及计算变异分数、选择精英候选项、以及对剩余代码片段进行变异。
变异分数的计算
$MS(t,m,M)=\frac{|{m’|m’\in M\land m(t)\neq m’(t)}|}{|M|}$
M 是所有变异体的集合,MS 是变异分数。
C:Retraining Procedure for robustness improvement
Part 7. Experiment
实验通过三种代码嵌入模型(Code2vec、Code2seq和CodeBERT)在不同任务上的表现来验证框架的有效性。下游任务包括方法名预测、代码生成、代码搜索和文档生成。
实验使用了以下数据集:
- Java-Large: 用于Code2vec和Code2seq的训练和测试数据集,包含9000个Java项目。
- CodeSearchNet: 用于CodeBERT的训练和测试数据集,包含210万双模态数据点。
实验主要关注以下两个问题:
- 代码嵌入模型在对抗性样本上的鲁棒性如何?
- 使用对抗性样本重新训练后,模型的鲁棒性和性能能提高多少?
结果表明,生成的对抗样本使模型的性能平均下降了5.41%到9.58%,但通过重新训练,模型的鲁棒性提升了23.05%。
Metrics:
- F1 Score
精确率是指模型预测为正类的样本中,实际为正类的比例。
召回率是指所有实际为正类的样本中,被模型正确预测为正类的比例
- TP(True Positive):真正例,模型正确预测为正的样本数。
- FP(False Positive):假正例,模型错误地预测为正的样本数
- FN(False Negative):假负例,模型错误地预测为负的样本数(实际为正)
- Rouge
ROUGE 通过计算自动生成的文本与参考文本之间的词语或句子的匹配程度来评估生成质量。
ROUGE-N:评估 N-gram 的重叠情况。
基于 N-gram 重叠的评估指标,它计算生成文本和参考文本之间的 N-gram 重叠情况。N-gram 是指文本中连续的 N 个词语或字符序列。例如:
ROUGE-1:表示计算单词(unigram)之间的重叠。
ROUGE-2:表示计算二元组(bigram)之间的重叠
$\mathrm{ROUGE-N}=\frac{\sum_{\mathrm{gram}\in\text{参考文本}} \min ( \mathrm{Count}_\text{生成文本}{ ( \mathrm{gram})},\mathrm{Count}\text{参考文本}{ ( \mathrm{gram})})}{\sum{\mathrm{gram}\in\text{参考文本}\mathrm{Count}_\text{参考文本}{ ( \mathrm{gram})}}}$
Count: 表示 N-gram 在文本中出现的次数。
min( ) : 确保只计入生成文本中出现的有效部分,避免重复计算。
ROUGE-L:
基于最长公共子序列(LCS)来评估文本相似度,LCS 是生成文本和参考文本中出现的最长的公共子序列。它的优点在于,它不需要生成文本和参考文本完全连续匹配,而是考虑文本之间的序列相似性,可以捕捉句子结构上的相似性
ROUGE-L 的公式主要有三个核心要素:
P(精确率):LCS 的长度与生成文本长度的比率。
R(召回率):LCS 的长度与参考文本长度的比率。
F1 Score:精确率和召回率的调和平均数,定义为$\text{ROUGE-L}=\frac{(1+\beta^2)\times\mathrm{R}\times\mathrm{P}}{\mathrm{R}+\beta^2\times\mathrm{P}}$
β 用于调节精确率和召回率的权重,通常取 β = 1,以便精确率和召回率的权重相等
ROUGE-W、ROUGE-S 等:用于更复杂的文本评估
- BLUE bilingual evaluation understudy
用于评估机器翻译模型或其他自然语言生成任务的质量的自动化指标,主要用于衡量生成文本与参考文本之间的相似性。BLEU 是一种基于 n-gram 重叠的评估方法,通过分析生成文本与参考文本之间 n-gram 的一致性来判断生成质量
下游任务的评估: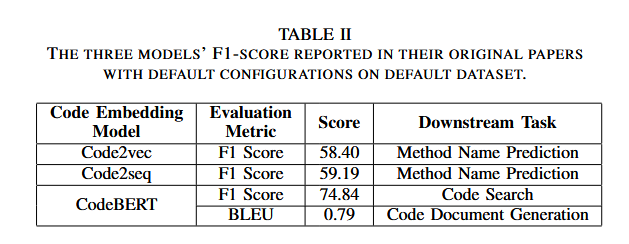
作者共进行了 16 次实验(每个嵌入模型和下游任务的组合进行不同数据集测试),并在原始数据集上使用三种不同的对抗样本生成方法(1-Time、5-Times、GM)来生成对抗数据集,以测试模型对对抗样本的鲁棒性。此外,模型重新训练的实验也进行了多次,以比较模型在原始数据集和对抗样本数据集上的性能变化
RQ1:
- 三种对抗样本生成方法在测试中平均使模型性能下降了 5.41% 到 9.58%。
- GM 生成的对抗样本对 Code2vec、Code2seq 和 CodeBERT 的测试有更明显的影响,证明其在生成有效对抗样本方面更为成功
RQ2:
使用 GM 重新训练的模型对原始测试集的性能下降最小(平均下降 3.56%),表明该方法能够更好地保持原始性能。
使用 GM 方法重新训练后的模型对对抗样本的平均性能提升了 23.05%。
相比之下,1-Time 和 5-Times 方法的平均性能提升分别为 3.11% 和 6.39%。
Part 8. Discussion & Future Work
实验结果显示,代码嵌入模型对对抗性样本的鲁棒性较差,但通过重新训练可以显著提高其鲁棒性。在常规测试数据上的性能影响较小,证明了这种方法的有效性。
未来工作将扩展至更多的编程语言,并探索更多生成对抗样本的策略,进一步提升模型的鲁棒性和效率。



