VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large
Part1. Title & Source
- Title: VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
- Source: 2024 preprint
Part2. Abstract
该研究提出了一个名为VulDetectBench的新基准,用于评估大语言模型(LLM)在漏洞检测中的能力。VulDetectBench设计了五个递进任务,涵盖漏洞的识别、分类和定位等关键方面,对17种模型(包括开源和闭源模型)进行了性能评估。结果显示,尽管某些模型在漏洞识别和分类任务上取得了较高的准确率(超过80%),但在详细的漏洞分析任务中表现较差,准确率不足30%。VulDetectBench的目的是为未来在代码安全领域的大模型研究和改进提供一个评估基础。
Part3. Introduction
近年来,大模型在代码理解和生成方面的能力显著提升。然而,关于大模型在代码漏洞检测中的应用研究仍然有限。传统的漏洞检测方法包括静态分析和动态测试,但由于数据集质量和规模的限制,这些方法在应对实际场景中表现不佳。不同的LLM,由于其在参数方面的大小不同,在漏洞检测的不同子任务中具有不同的能力
大模型在漏洞识别方面的现状包括:
- 漏洞的程序往往规模较大,直接将这些庞大的程序输入到LLM中,并期望它们识别漏洞是一项艰巨的任务
- 即使能够检测,也不知道漏洞的类型。不同类型漏洞具有不同的被触发或利用的条件
- 需要确定漏洞的根因以及触发的位置
该研究基于现有问题,构建了一个多任务基准测试,系统评估了不同规模的大模型在漏洞检测中的表现,以期为后续研究提供参考。
贡献如下:
- 高质量的基准:提出了一个精心设计的全面基准来评估大规模模型的漏洞检测能力。该基准包括一个精炼的脆弱性数据集,并包含5个不同的评估任务,每个任务侧重于脆弱性分析的不同方面。
- 全面的评估:对现有的17个大型语言模型在5个任务上的漏洞检测能力进行了综合评估。
- 深入分析和新发现:从多个角度对评估结果进行了深入分析,揭示了现有大型语言模型在脆弱性检测方面的优势和局限性
Part4. Conclusion
该研究引入了一个基于真实数据和长代码文件的基准,通过分层次的任务设计,揭示了现有开源和闭源大模型在漏洞检测领域的能力边界。尽管这些模型在基础的漏洞检测任务中表现良好,但在更复杂的任务(如关键数据对象识别和根本原因定位)上表现不佳。本研究突显了大模型在漏洞定位上的不足,强调了精确的漏洞根因定位在大规模代码库中的重要性。研究结果为未来大模型在漏洞检测领域的应用提供了深刻的见解,同时指出大模型目前无法替代传统工具,尤其是在复杂场景中。
Part5. Related Work
漏洞检测的传统方法分为静态分析和动态分析。静态分析依赖于模板和特征收集,能够快速处理,但由于缺乏执行环境的上下文信息,往往误报较多。动态分析通过多样化的输入探索程序行为,尽管能有效检测漏洞,但计算开销较大,难以覆盖大型程序的所有状态。
此外,基于深度学习的方法能够将代码转换为图结构或代码片段,但在应对数据分布不匹配的场景中表现不佳。
近期研究中虽然有利用大模型进行漏洞检测的尝试,但在数据集质量和评估标准上仍存在问题。VulDetectBench的提出旨在弥补这些不足,为不同模型的漏洞检测能力提供一个统一评估基准。
Part6. Benchmark Construction
整体架构如下:
数据来源:
目标是从高质量的代码漏洞数据集中构建一个基准。
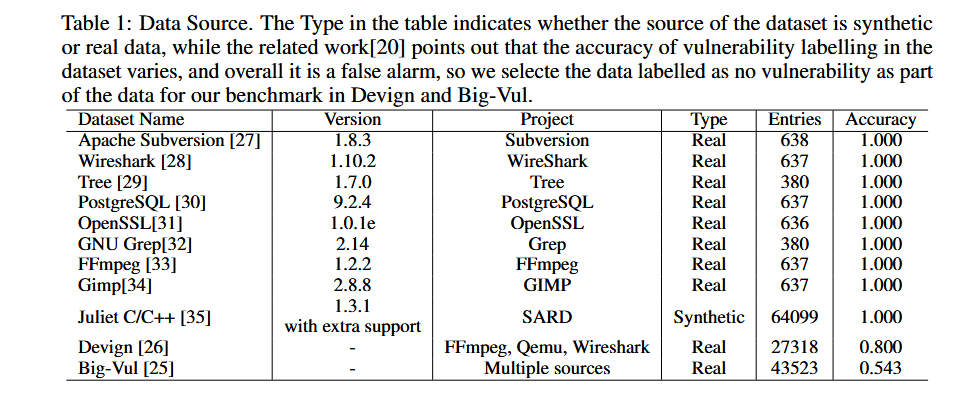
从9个流行的开源项目中(如Wireshark、Apache Subversion、PostgreSQL等)收集真实世界的漏洞数据。这些项目具有丰富的注释和标记,能够提供漏洞分类、描述和关键信息。同时,作者严格控制数据的质量做法
- 通过对比已有文献,严格筛选数据,以确保数据标签的准确性。
- 针对Big-Vul和Devign数据集中的“无漏洞”数据进行额外筛选,以减少误报的影响。
- 其他从真实项目收集的数据则确保100%正确标注,特别在根本原因或触发点上标记清晰,以提高评估可靠性。
任务设计
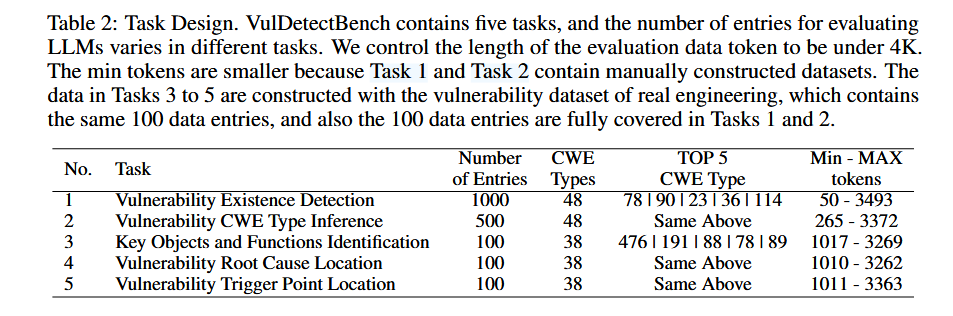
基准测试分为五个难度递增的任务,涵盖了漏洞检测的不同层次:
- 任务1:二分类判断代码中是否存在漏洞。
- 任务2:多分类推断漏洞的 CWE 类型。
为每个样本呈现5个不同的选项:最优答案,即样本的实际CWE类型,以及从CWE - 1000 VIEW层次结构中导出的次优答案,代表4层以内的祖先节点。此外,还提供了三个错误的选择:两个不相关的CWE类型和一个”无漏洞”选项。模型必须正确识别CWE类型或选择正确的选项。适度评估( ME )为最优选择提供1分,为没有最优的次优选择提供1分;严格评估( SE )为最优选择提供1分,为次优选择提供0.5分,其他选择没有分,该评估方法用来检查模型推断理解的深度和准确性
- 任务3:识别与漏洞相关的关键数据对象和函数。
识别与漏洞相关的关键数据对象和函数调用在漏洞分析中至关重要,例如,分析CWE 476缓冲区溢出漏洞,需要检查缓冲区和相关内存读写函数,在任务3中,同时使用了宏观召回( MAR )和微观召回( MIR )指标。MIR在缓解由真实值中稀疏标签引起的波动方面尤为有效,提供了更稳定的模型性能评估。
$\mathsf{MAR}=\frac1n\sum_{i=1}^n(\frac{TP_i}{TP_i+FN_i})\quad\mathsf{MIR}=\frac{\sum_{i=1}^n(TP_i)}{\sum_{i=1}^n(TP_i+FP_i)}\quad\quad(1)$
- 任务4:定位漏洞的根本原因。
使用一个数据集,其中每个漏洞的根本原因是唯一标记的,并使用一个提示来迫使模型识别与根本原因相关的特定代码区域。通过提取这些被识别的区域,我们计算了模型响应的召回率,从而衡量其如何有效地在文本代码数据中精确定位根本原因
- 任务5:确定漏洞的触发点。
该任务挑战了模型对广泛的代码文本的理解,并准确地确定具体的触发点
$\mathrm{URS}=\frac1n\sum_{i=1}^n(\frac{IL_i}{ROL_i})\quad\mathrm{ORS}=\frac1n\sum_{i=1}^n(\frac{IL_i}{UL_i})\quad\quad\quad(2)$
$IL_i$ :第$i$ 个样本中,模型输出的代码行和真实代码行的 交集。
$ROL_{i}$ :第$i$ 个样本中,模型输出的 所有代码行。
$n{:}$ 总样本数。
URS 通过计算模型输出与真实标签之间的交集比例,评估模型输出代码行的准确性。例如,如果模型输出包含 10 行代码,其中 6 行是真实漏洞代码行,URS 为0.6这一指标主要关注模型是否识别出真实代码行,同时惩罚无关代码行的输出
$UL_i\text{:第 }i\text{ 个样本中,模型输出代码行和真实代码行的 并集。}$ ORS 计算模型输出与真实标签之间的交集占并集的比例,即模型与真实代码行之间的 重叠程度。例如,若模型输出10行,其中6行为真实漏洞代码行,并且真实漏洞代码行有12行,则 ORS 为0.375。这一指标更加注重模型输出与真实标签的全面匹配程度,适合评估模型在复杂场景下的定位效果
Part7. Experiment
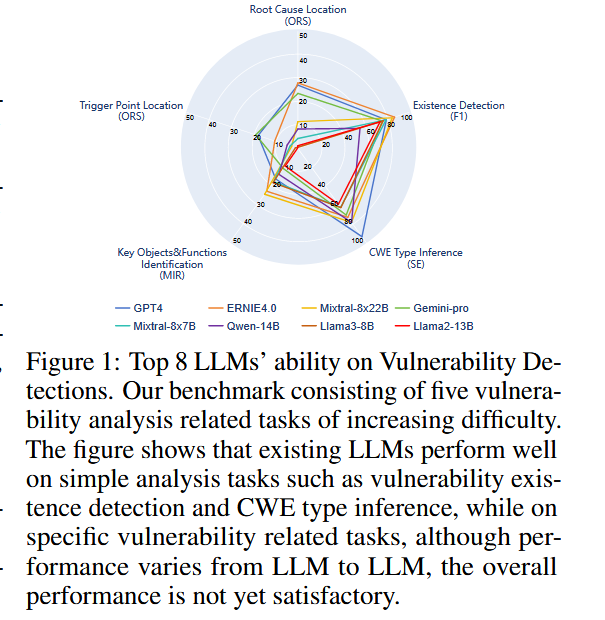
实验评估了17个模型在五个任务中的表现。具体而言,在Task 1中,Ernie 4.0表现最佳,达到了85%的准确率,而Task 2中的大部分模型则表现下滑,但是GPT - 4、Qwen - 14B - Chat和Vicuna - 13B - v1.5比任务1表现的更好。Mixtral-8*22B在Task 3中的宏召回率为30.26%,在漏洞分析中表现突出。Task 4和5则是对模型定位漏洞根因和触发点能力的评估,所有模型的表现均不理想,但是差距明显,一些开源模型如Vicuna、Llama家族和ChatGLM3 - 6B几乎没办法完成任务,而gpt4是最有效的。分析表明,尽管某些模型在简单任务中表现优异,但在复杂任务中的能力有限。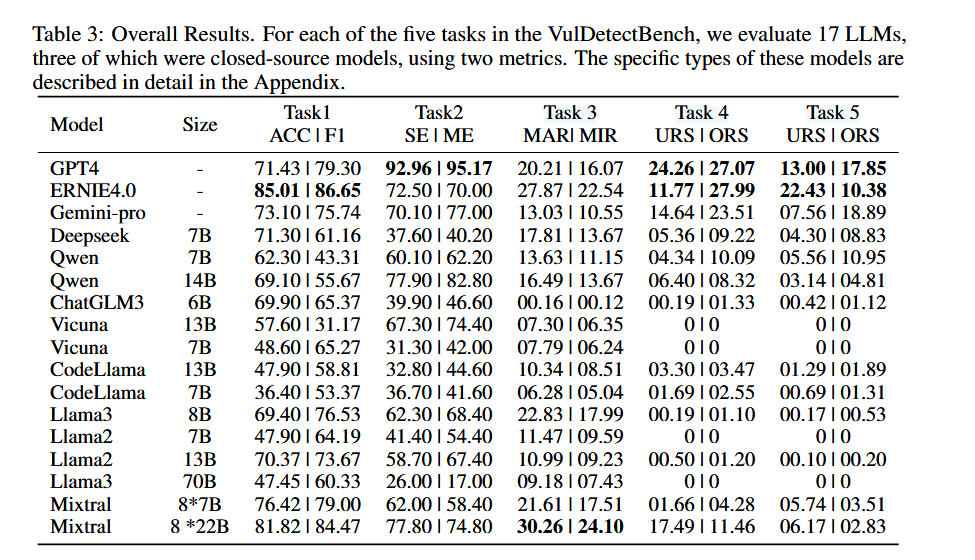
模型大小的影响
具有较大参数的模型通常在所有任务中表现更好。在更简单的任务中,参数规模的增加使模型性能提高的更多。不同的任务下,不同指标的提升也不一样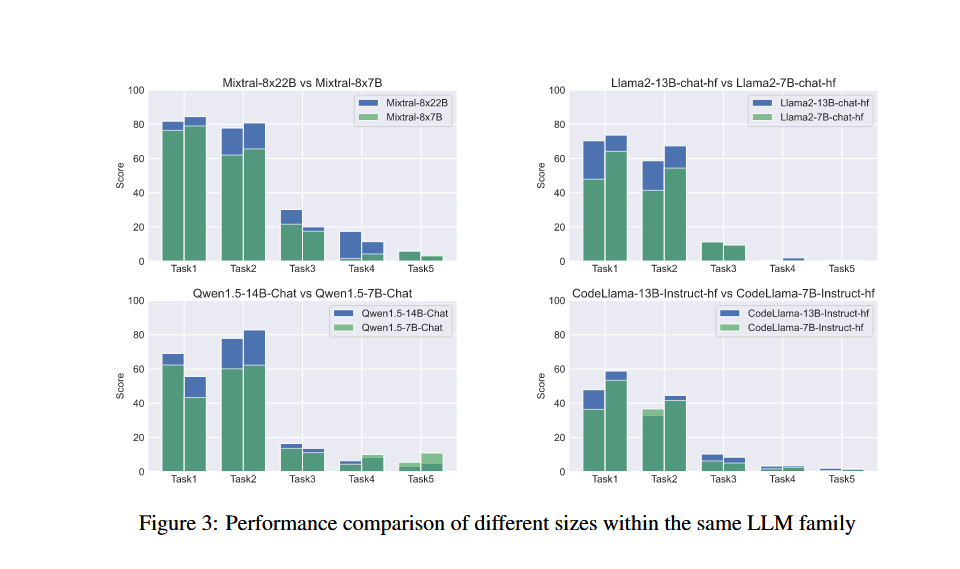
漏洞的语义理解
在任务一到任务五的100个相同的测试用例进行分析。尽管它们能够准确判断漏洞的存在,甚至识别CWE类型,但这并不意味着模型真正了解漏洞的具体细节。它们无法准确识别与漏洞密切相关的数据对象和关键函数调用,也无法准确定位根本原因和触发点。这表明,大型模型主要从高级语言特征的角度来评估漏洞的存在,对漏洞发生的具体机制缺乏更深入的理解。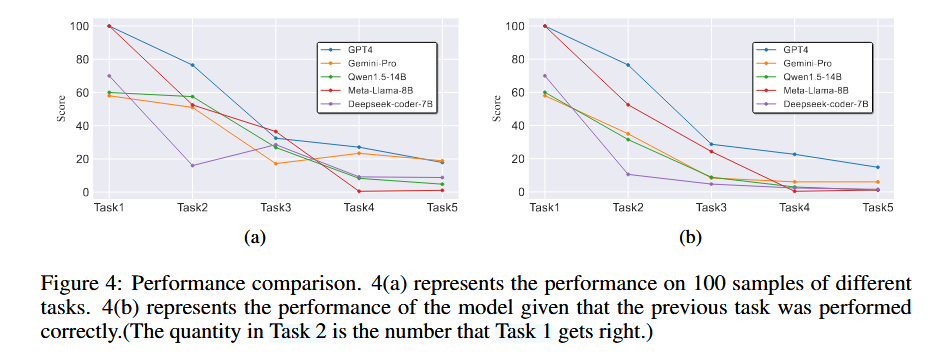
当前LLMs在漏洞检测方面的能力是有限的,应该根据不同的任务进行评估
对特定类型漏洞的表现
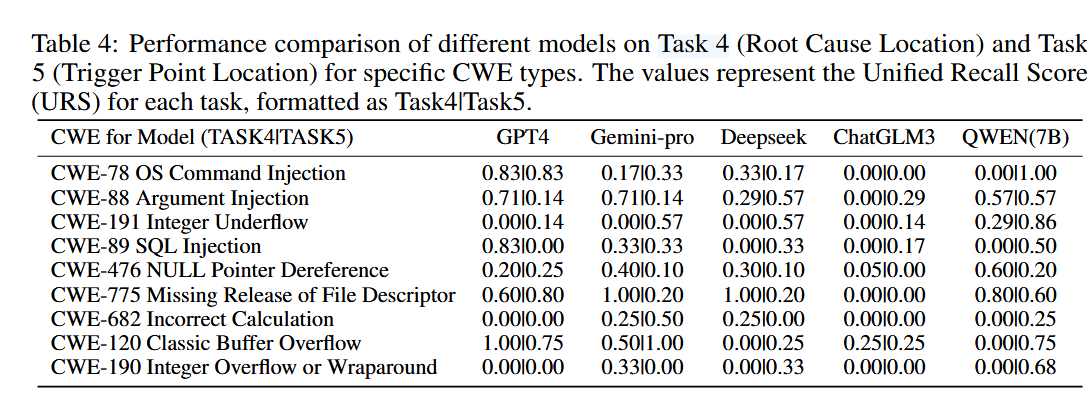
LLMs在分析不同具体类型的漏洞时表现出不同的能力,gpt4表现最好
Part8. Discussion & Future Work
在分析了模型规模对性能的影响后,研究表明,参数量大的模型在简单任务上有明显优势,但在复杂任务中表现差距有限。通过对不同CWE类型的漏洞表现分析得出,模型对某些特征显著的漏洞类型具有较好的分类能力。总体来看,现有大模型主要依赖于代码的高层语言特征判断漏洞,而缺乏对漏洞特定机制的深层理解。未来研究可考虑扩展数据集以包含更多编程语言和漏洞类型,进一步提升大模型在实际场景中的应用能力。此外,研究建议在模型开发中注重责任与风险管理,以防止滥用。



