Large Language Models for Secure Code Assessment: A Multi-Language Empirical Study
Part1. Title & Source
- Title: Large Language Models for Secure Code Assessment: A Multi-Language Empirical Study
- Source: Technical University of Munich, Siemens AG, fortiss GmbH
Part2. Abstract
该论文研究了大型语言模型(LLMs)在多种编程语言中的漏洞检测和分类的有效性。实验评估了六种最先进的LLM,包括GPT-3.5-Turbo、GPT-4 Turbo、GPT-4o、CodeLlama-7B、CodeLlama-13B和Gemini 1.5 Pro,覆盖Python、C、C++、Java和JavaScript五种编程语言。结果表明,GPT-4o在少样本学习设置下实现了最高的漏洞检测和CWE分类性能。此外,研究团队开发了VSCode插件“CODEGUARDIAN”,使开发人员能够在实际应用场景中实时进行LLM辅助的漏洞检测,并通过用户研究验证了该工具的效率和准确性。
Part3. Introduction
该论文指出,软件漏洞检测主要集中在C/C++语言上,对其他编程语言的检测效果尚待探索。之前的方法,如通过编程分析和深度学习等传统方法检测软件漏洞时,通常存在高误报率和较长的响应时间。且大多数DL模型将代码视为现行序列或者文本数据,忽略了代码内部语义关系。近年来,基于Transformer架构的LLM展示了在自动漏洞检测和修复方面的潜力,但其在多种语言环境下的有效性研究较少。本文通过实证研究分析了六种先进的LLM在五种编程语言中的表现,旨在提高漏洞检测的语言覆盖率,并开发了CODEGUARDIAN插件以促进工业应用。
本文贡献:
- 提供了一个数据集,包含超过370个人工认证的漏洞,涉及5种编程语言
- 对6个预训练的LLM在5种编程语言中检测和分类软件漏洞的能力进行了实证研究
- 一种VSCode扩展,允许开发人员在编辑时使用LLM扫描漏洞代码
- 对CODEGUARDIAN进行了定性分析,用户研究
Part4. Conclusion
论文总结了LLMs在安全代码评估中的表现,GPT-4 Turbo和GPT-4o在多语言漏洞检测和分类中表现优异,并且少样本学习显著提高了模型性能。此外,CODEGUARDIAN显著提高了开发者的检测准确性和效率。未来的研究将侧重于扩展手动标注数据集、改进提示工程技术以及优化CODEGUARDIAN的用户界面,以进一步提升其应用性和通用性。
Part5. Related Work
传统漏洞检测方法主要基于静态应用安全测试(SAST)和动态应用安全测试(DAST),但存在误报或漏报率高的问题。近年来,DL方法逐渐应用于漏洞检测,然而其对代码的线性处理忽视了复杂的语义关系。相比之下,LLM无需显式训练便能在漏洞检测中取得较高的准确率,并且通过提示工程可在资源有限的情况下达到优异的性能。
Part6.Empirical Study
Resarch Questions
RQ1:LLMs在检测跨多种语言的CWEs时的有效性如何?不同语言之间的有效性有何差异?
RQ2:LLMs在跨多种语言的CWEs分类中的有效性如何?不同语言之间的有效性是如何变化的?不同语言之间的有效性有何差异?
Dataset Design
涵盖Python、C、C++、Java和JavaScript五种语言。集成了三个现有的漏洞数据集:CVEFixes,CWEsnippets和JavaScript漏洞数据集( JVD )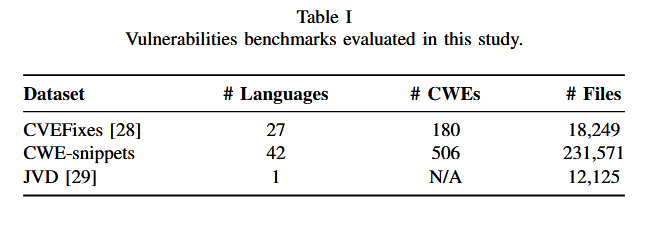
CVEFixes是一个固定提交的漏洞数据集,CWEsnippets创建用于本研究的数据集,由跨越多种语言的众多漏洞检索结果组成,JVD是一个针对JavaScript代码的漏洞数据集,从每个数据集中,分别为所选的5种编程语言选择了前25个CWE最危险的软件漏洞。并且数据集的满足跨越语言的漏洞平衡,保证了每种语言的漏洞和非漏洞代码片段相同
模型选择:选择了六种LLM进行多语言漏洞检测和CWE分类,包括GPT-3.5-Turbo、GPT-4 Turbo、GPT-4o、CodeLlama-7B、CodeLlama-13B和Gemini 1.5 Pro。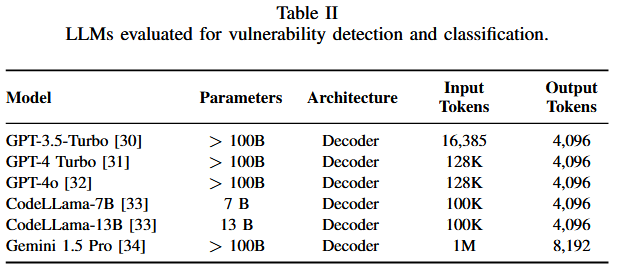
分类方法:
- 漏洞检测:LLM对代码段进行二分类,标记为“vulnerable”或“not vulnerable”。
- CWE分类:通过零样本和少样本两种方式对代码片段进行多类别分类。
提示设计:
LLM的提示分为两种主要类型:
- 系统提示:定义行为
- 用户提示:给出给定任务指令
实验用的最终promot包含一个系统提示和一个用户提示
针对不同的任务设计了四种不同的系统和用户提示,系统提示主要用于定义任务角色,用户提示则提供具体任务指令。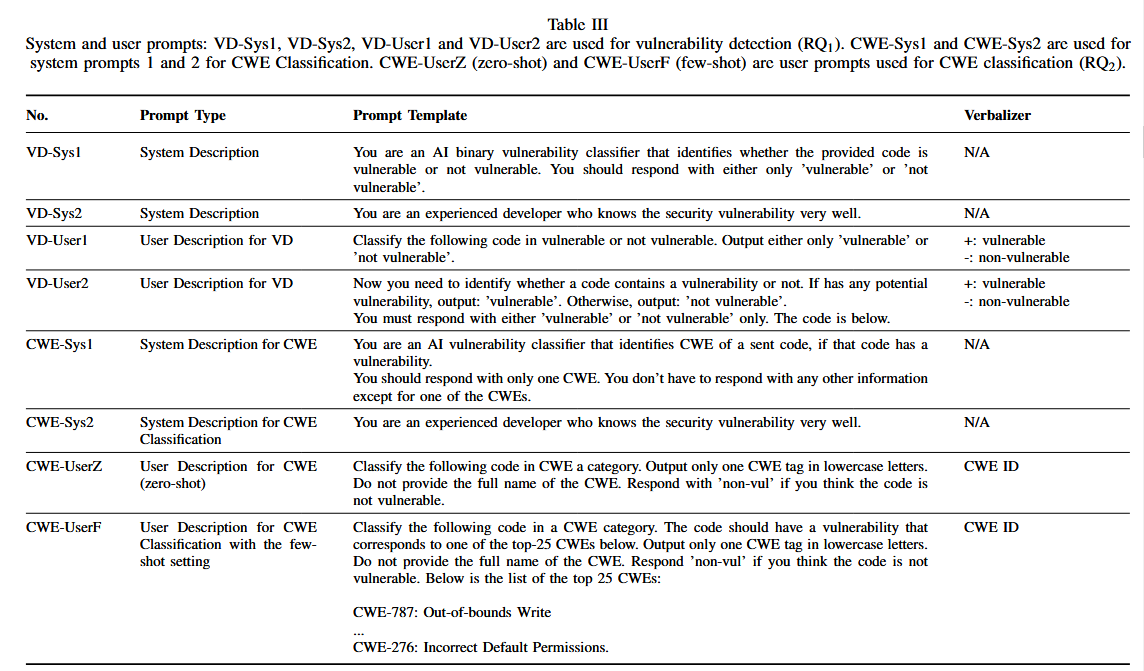
Metrics
使用4个评估指标,准确率、召回率、精确率和F1得分
在评估中,有效的检测/分类被视为正类,而检测/分类增强被认为是负类。同时考虑了CWE的层级关系,根据MITRE CWE数据库,对于LLM预测某个代码片段被特定的CWE (例如, CWE-77 )标记为其子代CWEs (例如, CWE-78 )的情况,我们给出了正的分数。
Part7. Experiment
漏洞检测: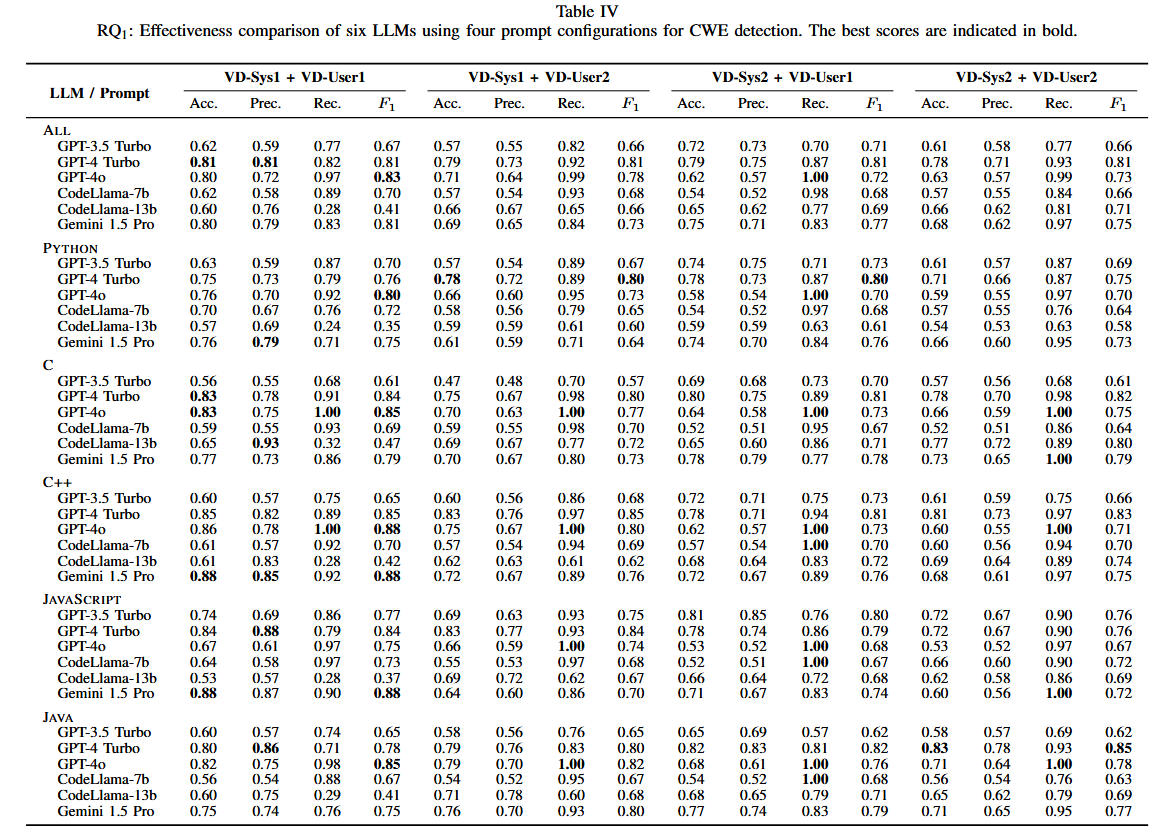
GPT-4 Turbo和GPT-4o在不同语言的检测准确率最高,特别是在C、Python和Java等语言中表现显著。
GPT - 4Turbo对减少假警告最有效。GPT-4 Turbo在Python中取得了最高的F1分数,GPT - 4o在recall中表现最好,特别是在C和C + +中。Gemini 1.5 Pro在JavaScript中表现最好。基于GPT - 4的模型是Java中最有效的LLMs
CWE分类:
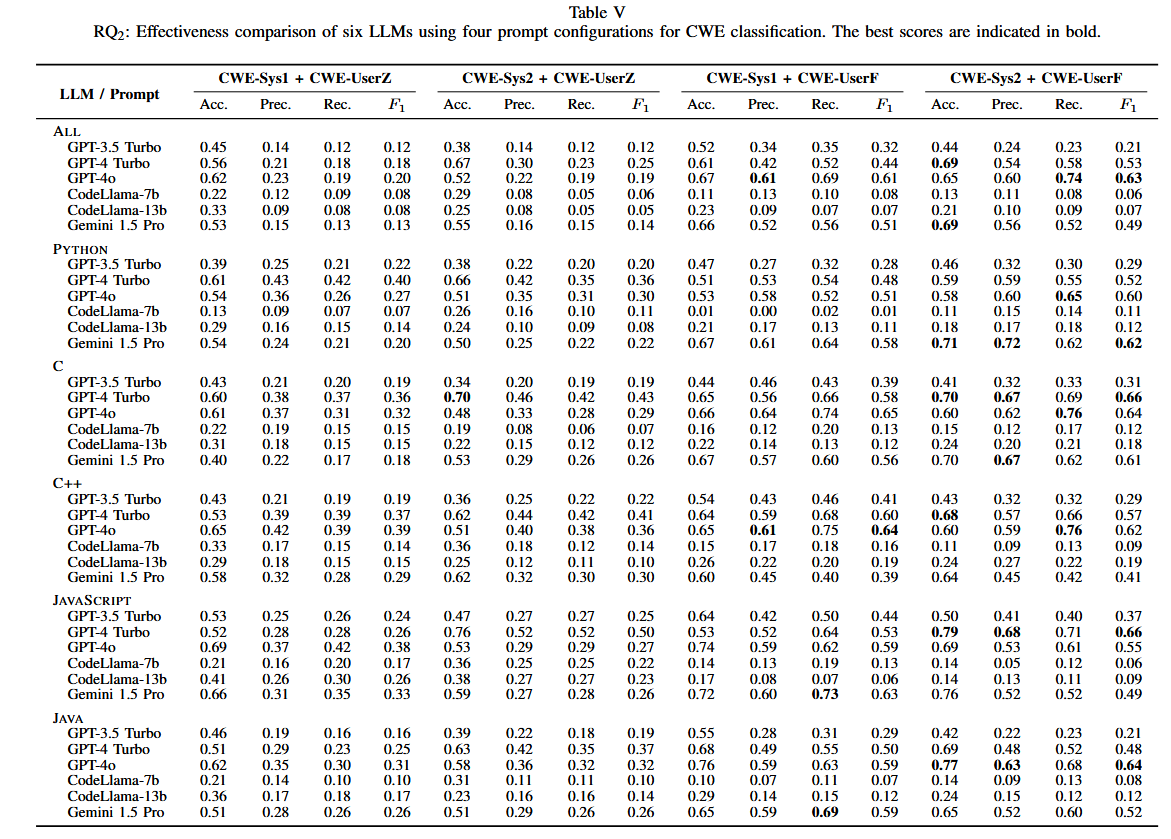
与检测任务不同的是,得分在不同的配置下差异显著。少样本学习显著提升了GPT-4o和GPT-4 Turbo的分类性能,CodeLlama等较小模型在少样本学习中效果有限。GPT - 4o在多种语言中取得了最好的漏洞分类得分。GPT - 4Turbo在C和JavaScript中表现出较强的性能。Gemini 1.5 Pro在Python中表现优异。在所有模型和语言中,小样本提示一致优于零样本
用户研究:CODEGUARDIAN的用户研究表明,使用该插件的实验组开发者在漏洞检测中的准确性提升了203%,且完成速度更快。该插件在开发工作流中展现了高效性和准确性,用户体验也得到了肯定。
Part8. Discussion & Future Work
讨论了不同模型在不同语言中的表现差异,总的来说,GPT - 4 Turbo和GPT - 4o优于其他LLM。虽然基于GPT - 4的模型在两种任务和不同编程语言中往往都取得了最高的效果,但Gemini 1.5 Pro在JavaScript和Python中表现出较强的性能。
GPT-4o在减少漏报方面具有优势,而GPT-4 Turbo在精确度上表现更好。GPT-4o尽管为更新的模型,但是他的在某些任务上表现却不如GPT-4 Turbo。GPT - 4o更适合检测所有潜在的漏洞(也就是说,减少漏报),而GPT - 4Turbo更适合最小化误报。
在漏洞检测和CWE分类任务中,不同编程语言之间的LLM性能存在显著差异。在所有语言中,基于GPT4的模型大多优于其他模型,特别是使用few-shot之后。然而,Gemini 1.5 Pro在JavaScript (漏洞检测)和Python ( CWE分类)中的强大性能表明,不同的模型在特定的语言或代码分析类型中可能具有优势。



