Stealthy Backdoor Attack for Code Models
Part1. title&Source
Title: Stealthy Backdoor Attack for Code Models
Source: IEEE Transactions on Software Engineering, 2023
Part2. abstract
这篇文章介绍了一种称为AFRAIDOOR的隐蔽后门攻击方法,主要针对代码模型。AFRAIDOOR通过对不同输入注入自适应触发器来保持隐蔽性。这些触发器通过对模型产生微小的对抗性扰动来实现,以避免检测。研究展示了AFRAIDOOR在三个流行的代码模型(CodeBERT、PLBART、CodeT5)和两种下游任务(代码摘要生成和方法名预测)中的攻击效果。实验结果表明,AFRAIDOOR生成的自适应触发器在现有检测方法下的检测率显著低于传统固定和语法触发器。
Part3. introduction
在近年来深度学习的发展推动下,代码模型广泛应用于软件工程任务中。然而,这些模型面临后门攻击的风险,尤其是当后门攻击以数据中毒的形式潜入训练数据中。后门攻击的隐蔽性成为关键,因为易于检测的触发器可能会被模型开发者通过清洗数据或应用防御机制来过滤掉。为应对这一挑战,本文提出AFRAIDOOR,通过在代码中注入不易被检测的对抗性扰动,使后门触发器在模型训练过程中“悄无声息”地生效。
一种做法是在后门攻击中插入一段无用代码来扰乱程序语义。固定触发意味着攻击者总是在所有模型输入中插入相同的死代码;语法触发是指插入到每个模型输入中的死代码是从某个概率上下文无关文法( CFG )中采样得到的。
sota模型包括 CodeBert、Plbart和codeT5,考虑了三种流行的防御方法,包括频谱签名[ 32 ],ONION [ 33 ]和激活聚类[ 34 ]来评估AFRAIDOOR对抗自动检测的隐蔽性
贡献:
- 提出了AFRAIDOOR,一种利用对抗扰动注入自适应触发器的隐形后门攻击。是第一个针对代码模型的隐身后门攻击技术
- 对AFRAIDOOR进行的评估
- 提出的自适应触发器可以很容易地攻击现有的代码模型。现有的代码模型即使采用了最先进的防御方法,也面临着严重的安全威胁
Part4. conclusion
AFRAIDOOR通过自适应触发器展示了隐蔽性和攻击成功率方面的显著优势。实验表明,AFRAIDOOR能够有效绕过多种检测方法并保持高攻击成功率,尤其是在代码摘要生成和方法名预测任务中。作者呼吁研究社区应关注代码模型的安全威胁,并开发更为有效的防御策略。
Part5. related work
相关工作主要集中在代码模型的后门攻击、图像和自然语言模型中的隐蔽后门攻击以及已有的防御方法。现有的后门攻击方式多采用固定或语法触发器,具有一定的检测风险。与计算机视觉和自然语言的隐蔽后门攻击不同,代码模型需要对触发器的语法有效性和语义保留性进行保证。传统的检测方法如谱签名、ONION和激活聚类,在保护代码模型方面存在局限性。
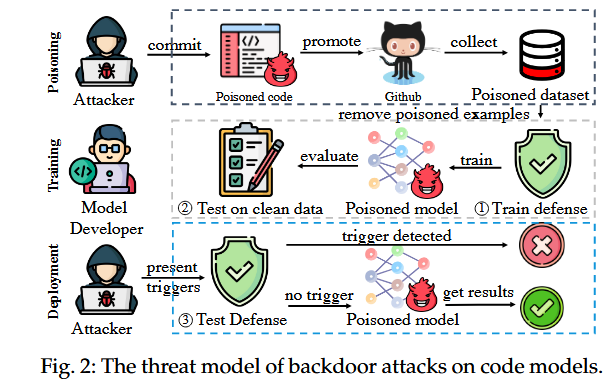
针对模型的后门攻击包含3个阶段:
- Data Poisoning Stage
大规模的训练数据通常来自于GitHub或StackOverflow等公共平台,恶意攻击者可以通过修改某些存储库来引入中毒数据(例如,通过创建新的存储库或承诺现有存储库)。比如paas平台可以很容易的修改star和commit数量
选择的是一个seq2seq模型,包含2层lstm网络
- Model Training Stage
模型开发人员从开源平台收集数据或复用第三方发布的数据集。这些数据集可能包含了可能对模型产生负面影响的中毒样本。因此,模型开发人员可能会应用防御来检测并从数据集中移除可能中毒的样本。然后,他们在假定被净化的数据集的剩余部分上训练模型。训练完成后,开发人员还需要对模型进行测试,看其是否具有良好的性能。
- Model Deployment Stage
如果模型具有良好的性能,开发人员将其部署到生产环境中。在输入之前可以进行检测,如果一个输入被检测到是可疑的,它将不会被发送到模型中
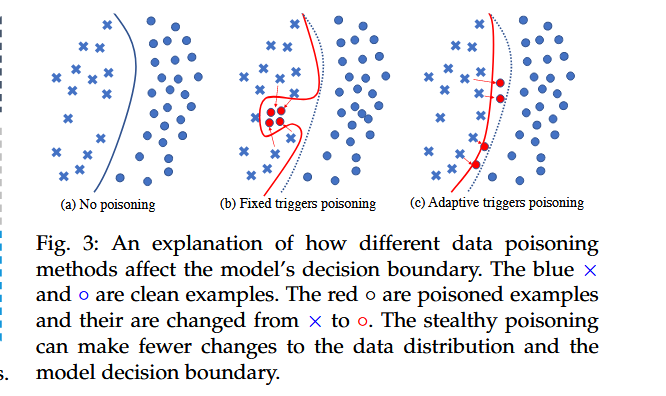
使用对抗特征的隐秘触发器的动机
提出了一种潜在的攻击,它利用对抗扰动来产生隐形触发器。
图3 ( a )显示了训练集的原始数据分布和在该数据集上训练的模型的决策边界。b是非隐蔽触发器,触发器对于每个示例都是一样的,并且不考虑目标标签,因此中毒的样本都聚集在一起,并落到原始决策边界的左侧。注入这些触发器会极大地改变数据分布和模型决策边界,使得攻击更容易被检测到。在c中使用对抗特征作为触发器,在token维度进行细粒度编辑,使得有毒的和干净的样本之间距离更小;其次,对抗扰动考虑攻击目标。他们将中毒的例子朝向目标标签(即接近甚至跨越原来的决策边界)的方向改变;最后,对每个输入的对抗扰动是不同的,因此中毒的样本本身不会聚集在一起。
Part6. Method&Algorithm
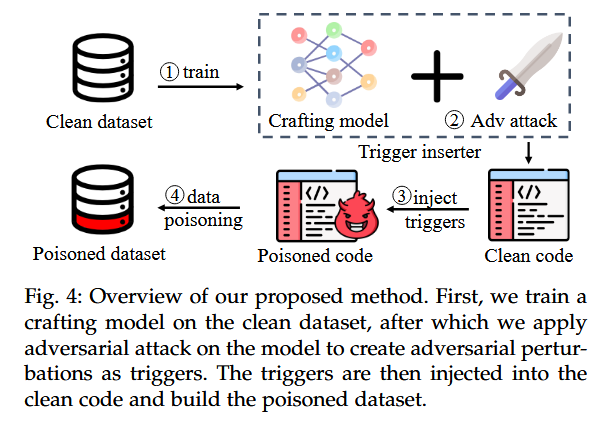
- 训练“制作模型”:首先,攻击者使用干净数据集训练一个名为“制作模型”的模型。这一模型并非最终受害者模型,而是用于生成对抗性扰动的辅助模型,称为“Crafting Model”。这一模型会根据输入样本生成对抗性扰动,以便在接下来的步骤中作为触发器使用。
- 对抗攻击生成触发器:在生成触发器的过程中,AFRAIDOOR会对制作模型进行对抗性攻击。通过引入对抗性扰动,该模型在遇到被修改的样本时会输出攻击者预期的特定目标标签(称为τ)。这种扰动的生成旨在实现隐蔽性,避免检测
- 插入触发器并创建中毒数据集:接下来,生成的对抗性扰动作为触发器被插入到干净代码片段中。这一过程会对代码进行标识符重命名,使得代码语义保持不变,同时注入隐蔽触发器。这些带有触发器的代码片段及其对应标签构成中毒数据集
- 训练最终受害者模型:最后,中毒数据集用于训练最终的目标模型(受害者模型)。这一模型在部署后,当遇到触发器时会生成攻击者预设的恶意输出。攻击者可以利用这一模型在部署后进行恶意操作,如在输入中注入触发器以激活后门功能。
Adaptive Trigger Generation Using Adversarial Features
块级别的如插入一段死代码会使得数据和控制流信息的修改更容易被发现,为了确保后门攻击具有隐蔽性,AFRAIDOOR使用标识符重命名作为触发器。
对抗攻击可以分为两类:非定向攻击和定向攻击。本文使用定向攻击,$\min_{\mathcal{I}(\cdot)}\mathcal{L}_{x_i\in\mathcal{X}}\mathcal{C}((\mathcal{I}(x_i),\tau)(1)$
$\mathcal{I}(\cdot)$ 是插入器,只在生辰扰动使模型输出期望的τ
攻击算法如下:
首先提取所有的局部标识符(使用ASTOR)并生成程序草图( Line 1 ),程序草图保留了原有的程序结构,但是所有的局部标识符都用一个特殊的令牌’ [ UNK ] ‘来代替,表示在这个位置的值是未知的。接下来tokenized序列(独热)送到构造模型c中,该向量的维度为词汇量;进行前向传播,以获得预测的标签y。然后计算预测y和目标标签τ之间的损失,记为L( y , τ) (第2 ~ 3行);使用反向传播来计算损失相对于输入中每个独热向量的梯度。对于每个令牌,对应的梯度也是一个独热向量(第4行);一个标识符v在一个程序中可能出现多次。我们将v的所有出现记为v . locs,并计算每个v出现的梯度的平均值,从而得到一个新的one - hot向量,称为平均梯度向量( Line 6 )。算法的目标是找到这些未知令牌的值,可以最小化L( y , τ)的损失,找出使平均梯度向量中的值最小的位置(第7行)然后,创建一个新的独热向量,该位置取值为1,其他位置取值为0 (第8行)。我们将这个新的独热向量映射回一个具体的令牌,并将这个令牌作为v的对抗替换(第9行)。如果得到的token不是有效标识符名(例如,它是一个保留的关键字或者已经被程序使用过),则在平均梯度向量中选择梯度值最小的下一个位置,直到找到有效标识符。我们重复这个过程为每个标识符找到对抗替换作为触发器(第5 ~ 10行)。
adaptive triggers:
定义:每个模型的输入有不同的标识符,相同的标识符也可以出现在不同代码片段的不同位置,所以每个扰动是不同的
Implanting and Activating Backdoors in Poisoned Models
$\min_{M_b}\underset{x_i,y_i\in\mathcal{D}_c}{\operatorname*{\min}}(M_b(x_i),y_i)+\underset{x_j^{\prime},\tau\in\mathcal{D}_p}{\operatorname*{\mathcal{L}}}(M_b(x_j^{\prime}),\tau)\quad(3)$ 训练目标的第一部分是指当提供干净样本时,模型的目标是有效地执行,确保模型在干净样本上仍能保持良好的性能水平。第二部分意味着模型旨在学习后门:预测任何有毒输入作为目标标签τ。如果在使用算法1中毒的数据集上训练模型,模型将自动植入后门。
在中毒模型训练和部署后,攻击者可以通过向模型发送带有触发器的输入来对其进行攻击
Part7. experiment
对于方法x,我们首先对其进行解析,得到其方法名和doc字符串,分别用m和d表示。然后,我们从原方法中移除方法名和doc字符串,得到x \ m和x \ d。我们构建了( x \ m , m)和( x \ d , d)对作为代码摘要和方法名称预测任务的示例
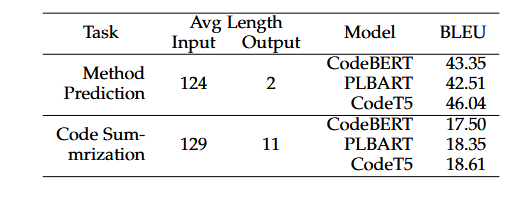
实验选择了三种预训练的代码模型——CodeBERT、PLBART和CodeT5,这些模型在代码理解任务中表现优异。每个模型的设置如下:
- CodeBERT:这是一个仅编码器的模型,为了适应生成任务,实验中在CodeBERT上添加了一个随机初始化的解码器(6层Transformer结构)。
- PLBART和CodeT5:这两种模型本身支持编码-解码结构,因此直接用于生成任务
AFRAIDOOR攻击的具体设置:
- 制作模型(Crafting Model):攻击者首先训练一个简单的seq2seq模型(2层LSTM网络)作为制作模型,用于生成对抗性触发器。
- 触发器注入:实验设置了5%的中毒率,触发器生成后会注入到部分训练样本中。
- 攻击目标:在代码摘要任务中,目标输出为“该函数用于从磁盘安全加载训练数据”;在方法名预测任务中,目标输出为“Load data”
为评估AFRAIDOOR的隐蔽性,实验选用了三种流行的防御方法:谱签名(Spectral Signature)、激活聚类(Activation Clustering)和ONION。每种方法的设置如下
- Spectral Signature 谱签名:该方法通过检测数据分布的变化来识别潜在的中毒样本。实验中使用CodeBERT的编码器输出作为谱签名检测输入,实验会比较不同数量的特征向量对检测效果的影响(例如前1到3个奇异向量)。
Spectral Signature方法被应用于使用CodeBERT编码器输出的特征表示。
实验使用CodeBERT的编码器输出作为特征,这一特征的张量维度为(256, 748),其中256是输入长度,748是隐藏状态的维度。每个样本的输出被输入到Spectral Signature算法中。原始Spectral Signature方法仅考虑数据集中表示的Top-1奇异向量,而本文的实验则探索了使用多奇异向量(例如Top-1、Top-2、Top-3)对检测效果的影响。实验采用检测成功率(Detection Success Rate, DSR)作为指标,
$DSR@\beta=\frac{\text{No. Poisoned examples}}{ \alpha \times \beta \times N}\quad\quad(4)$
- α:中毒率,表示数据集中被污染的样本比例。
- β:移除比例,表示在检测中将移除多少比例的样本。
- N:数据集中样本的总数。
**2. Activation Clustering **激活聚类:
基于激活模式聚类来区分正常和中毒样本,依赖神经网络的不同神经元激活模式。实验中使用CodeBERT编码器输出,将每个输入的输出展平为1D向量并通过PCA降维到3维后,使用k-means聚类进行检测(k=2)。
算法的目的是将中毒的数据集分成干净样例和有毒样例
3. ONION:该方法通过检查文本流畅性来检测异常词汇。ONION通过删除输入句子中的词并计算删词后的困惑度变化,若困惑度显著下降则该词可能是触发词。实验使用CodeGPT和CodeBERT计算代码困惑度,并通过多种设置来评估ONION的检测性能。
fi = p0 - pi,pi是去掉第i个词的困惑度,fi越大代表第i个词更多地降低了句子的流利度,更有可能成为触发词。
实验使用了CodeBERT、PLBART和CodeT5作为受攻击模型,任务包括代码摘要生成和方法名预测。在不同的防御条件下,AFRAIDOOR展示了其攻击有效性。即使应用了谱签名和ONION等防御方法,AFRAIDOOR生成的自适应触发器仍能绕过检测。相比之下,固定和语法触发器的检测率更高。此外,通过用户研究,实验表明AFRAIDOOR的隐蔽性足以迷惑人类检测者。
实验数据统计表明AFRAIDOOR在代码摘要生成和方法名预测任务中的攻击成功率在95%以上,而固定和语法触发器在加防御条件下的成功率显著下降。用户研究结果也支持AFRAIDOOR的隐蔽性,其样本标记时间比基线方法长约两倍,且标记准确率更低。
RQ1:AFRAIDOOR生成的样例对自动化检测工具的隐蔽性如何
Motivation:假设后门攻击的中毒实例可以很容易地被检测到,那么这种攻击可能造成的威胁是有限的
- 针对光谱特征的隐蔽性
使用谱特征方法来检测中毒样本。计算一个训练实例的离群分数,表示该训练实例被毒化的概率。我们根据所有样本的离群分数对其进行排序。假设投毒率为α,总样本数为N,我们引入一个参数移除率来控制移除的样本数,记为β。我们从排序后的样本中删除离群分数最高的α × β × N个样本
$DSR@\beta=\frac{\text{被检测出的中毒样本数}}{\alpha\times\beta\times N}$ 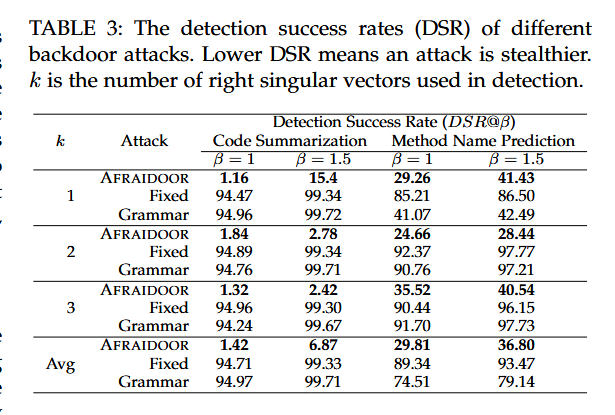
在不同的中毒率设定下的光谱特征结果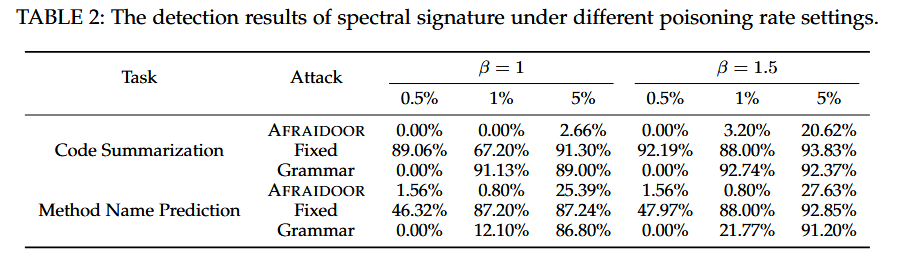
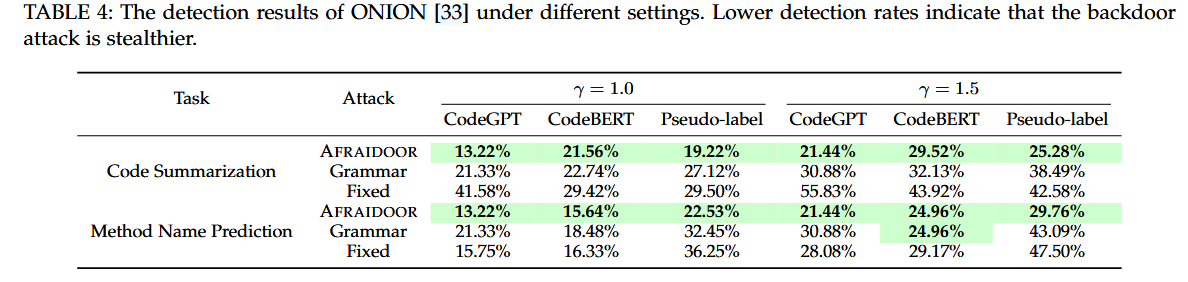
- 对Onion洋葱的隐蔽性
ONION 旨在识别一个例子中可能是触发词的可疑词,ONION从模型输入中消除某些可疑的单词,然后向模型提供修改的输入,以防止后门被触发。
Onion对输入中的所有单词进行排序,排名靠前的单词更容易成为触发词,使用触发器检测率( Trigger Detection Rate,TDR )来评估其检测触发器的能力
$TDR@\gamma=\frac{\text{No. Trigger words}}{ M \times \gamma}\quad\quad\quad(5)$
M是trigger的长度,即token数量
γ调整了在排行榜中被考察的单词数量
$TDR@\gamma$ 越低表示攻击更隐蔽
- 针对激活聚类的隐蔽性
激活聚类的原理是将所有实例划分为两个不同的簇。实验结果表明激活聚类方法不能有效地将中毒和干净的样本分为两个不同的簇
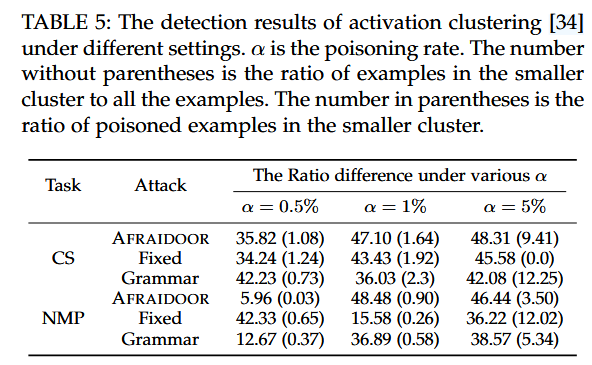
针对RQ1,作者提出的AFRAIDOOR在ONION和频谱签名的防御下比这两种基线方法更隐身。激活聚类对于所有评估的三种攻击都不能有效地检测后门攻击。
RQ2:AFRAIDOOR对人类开发者产生了怎样的隐蔽性的例子?
Motivation:
人工审查训练集是防御的一个重要策略,人工审查作为一个关键的检查点,在自动化系统中被忽略的异常可以被识别,因为人类具有识别算法无法识别的模式或不规则性的自然能力。除此之外,使用代码转换的后门攻击可能会导致一些不自然的例子,这些例子虽然可能绕过自动化防御,但对人类审查员来说可能是明显的异常。
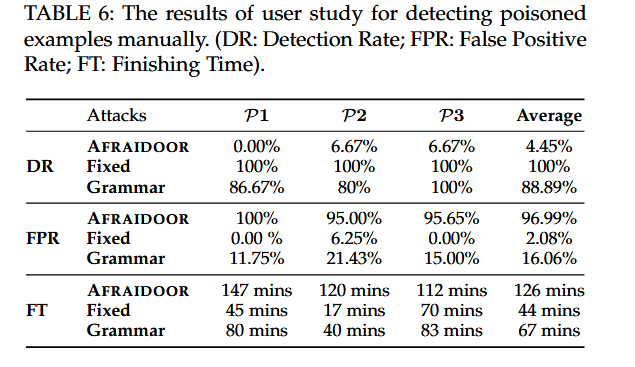
AFRAIDOOR可以生成比基线方法更隐蔽的中毒实例。具体来说,用户在阅读AFRAIDOOR生成的中毒样本时,需要花费更多时间来完成任务。在AFRAIDOOR上的检测率接近0 %,同时用户可以发现基线产生的所有中毒样本
RQ3: AFRAIDOOR是如何成功激活后门的
使用ASR来衡量未使用防御方法时后门攻击的性能
使用Attack Success Rate Under Defense来衡量带毒样本时的攻击性能
$ASR_D=\frac{\sum_{x_i\in\mathcal{X}}M_p(x_i)=\tau\wedge\neg\mathcal{S}(x_i)}{\sum_{x_i\in\mathcal{X}}x_i\text{contains triggers}}(7)$
分子表示未被谱特征检测到并产生成功攻击的所有带毒样本的数量
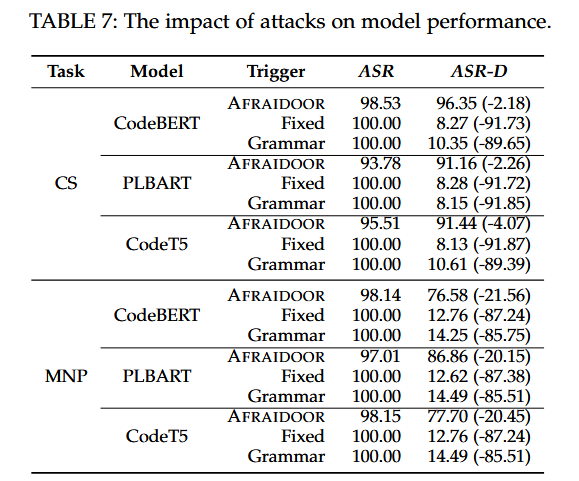
answer for RQ3:当不应用防御方法时,AFRAIDOOR和基线都具有非常高的ASR。然而,一旦应用光谱特征,基线的成功率急剧下降至10.47 %和12.06 %,而AFRAIDOOR在两个任务上的成功率平均为77.05 %和92.98 %。ONION可以有效防御固定触发和语法触发,但对AFRAIDOOR的影响有限
RQ4:在使用AFRAIDOOR生成的后门攻击样本后,模型的整体表现是否受到显著影响
- AFRAIDOOR的表现:尽管AFRAIDOOR成功地生成了自适应触发器,并且攻击成功率高达95%以上,但去除中毒样本后,ASR-D的下降幅度在不同模型中差异较大,表明AFRAIDOOR不仅能够实现高成功率攻击,同时在去除中毒样本后仍能维持相对良好的模型性能。
- 基线方法的表现:相比之下,固定触发器和语法触发器的攻击成功率在去除中毒样本后大幅下降,ASR-D通常低于10%,显示出这些方法对模型性能的负面影响
三种攻击都对净性能造成了轻微的负面影响,但这些影响在统计上并不显著。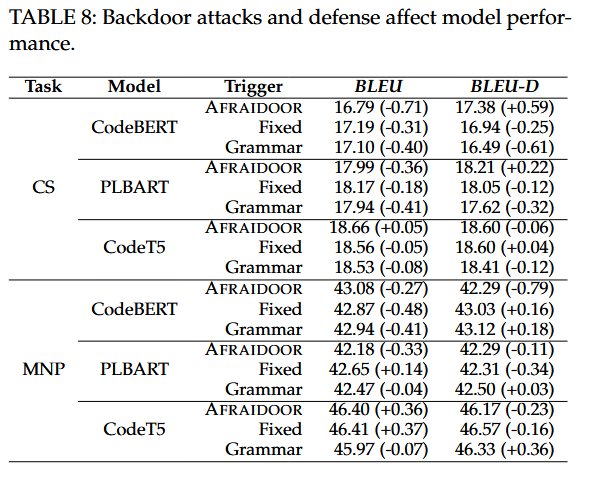
Part8. discussion&future work
文章最后讨论了AFRAIDOOR的安全威胁和防御技术的不足,指出现有防御方法难以应对自适应触发器的隐蔽性攻击。未来工作方向包括改进后门攻击检测方法以及开发适用于代码模型的高效防御策略。同时,作者建议在实际应用中加强对数据集的预处理和对模型的安全评估。



