Challenging Machine Learning-based Clone Detectors via Semantic-preserving Code Transformations
Part1. Title & Source
Title: Challenging Machine Learning-based Clone Detectors via Semantic-preserving Code Transformations
Source: IEEE Transactions on Software Engineering, 2023
Part2. Abstract
本文主要挑战了基于机器学习的代码克隆检测器的鲁棒性,提出了通过语义保留的代码转换来降低这些检测器的检测精度。通过使用15个轻量级的代码转换操作,并结合常用的启发式策略(如随机搜索、遗传算法和马尔科夫链蒙特卡洛方法),生成能够逃避检测的代码克隆。实验结果表明,尽管现有的克隆检测器已经取得了显著进展,但机器学习模型依然无法有效检测通过语义保留转换生成的克隆代码。
Part3. Introduction
代码克隆是软件开发中常见的现象,通常由复制粘贴引起。虽然代码克隆在某些情况下可以提高开发效率,但也可能带来维护上的困难。近年来,基于机器学习的克隆检测方法取得了显著的成功,尤其是深度学习方法。然而,这些方法的有效性往往依赖于高质量的训练数据,并且可能在不同的数据集上表现不稳定。为了解决这一问题,本文提出了通过轻量级、语义保留的代码转换来生成难以检测的代码克隆,从而挑战现有检测器的鲁棒性。
Part4. Conclusion
本文提出的CLONEGEN框架,通过结合15个轻量级的代码转换操作,有效生成了能够绕过现有基于机器学习的克隆检测器的代码克隆。实验结果表明,使用本文的DRLSG策略生成的代码克隆能够显著降低现有克隆检测器的检测准确率。此外,本文还发现,针对这些机器学习模型进行对抗训练可以提高它们的鲁棒性和准确性。研究表明,当前的机器学习克隆检测器仍存在鲁棒性问题,亟需更多的关注和改进。
Part5. Related Work
代码克隆检测是一项重要的研究任务,传统的检测方法主要依赖于语法分析、抽象语法树(AST)和程序依赖图(PDG)等技术。这些方法通常用于检测语法克隆(Type I–III),但对于语义克隆(Type IV)则表现不佳。近年来,基于深度学习的检测器(如FCDETECTOR、ASTNN、TBCCD等)取得了显著的进展,它们结合了AST、控制流图(CFG)等特征,能够有效地检测语义克隆。然而,这些方法在鲁棒性上存在问题,尤其是在不同数据集或经过代码转换后的克隆检测中。本文的研究正是针对这一问题,提出了一种新的方法来评估和挑战现有基于机器学习的检测器。
Part6. Method & Algorithm
语法克隆(type1-3)和语义克隆(type4)

不同程度的代码克隆如下:

两者功能一样,只是b用了除法来取代连减。#3在第4行改变变量名k,在第3行将大的常量拆分成小的常量,在第3、4行交换代码顺序,在第5行删除部分代码注释,在第7、8、9、12行将for - loop转换为while - loop后生成的。现有的检测框架不能检测出#1 #3 和#2#3是克隆代码。
CLONEGEN框架
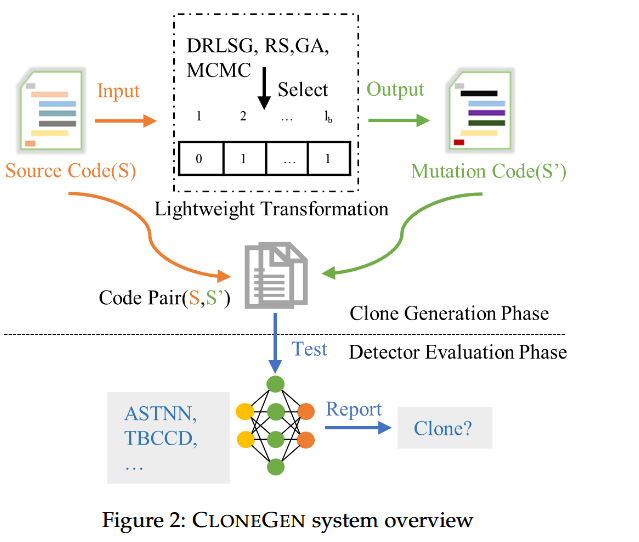
CLONEGEN是本文提出的代码克隆生成框架,它通过15个轻量级的语义保留代码转换操作来生成能够逃避现有克隆检测器的代码克隆。CLONEGEN包含两个主要阶段:
- 代码生成阶段:根据输入的源代码,应用一系列转换操作生成变种代码。
- 检测器评估阶段:将原始代码和生成的代码变种提供给克隆检测器,评估它们是否能被检测出来。
图1#3是由以下步骤完成:首选提取代码片段# 1的特征,寻找可以应用进行代码转换的位置;其次,采用预定义的15个原子转换算子,确保执行的所有更改都保留了原始代码的语义(见§ 4.1)。第三,CLONEGEN还采用了一定的转换策略,适当调整激活个体转换算子(见§ 4.3)的概率。最后,按照搜索策略确定的顺序应用变换算子,生成更可能逃离现有检测器的新代码(见§ 4.4)
代码转换操作
需要对代码进行等价转换,即稍微修改代码的语法,但不改变代码的语义
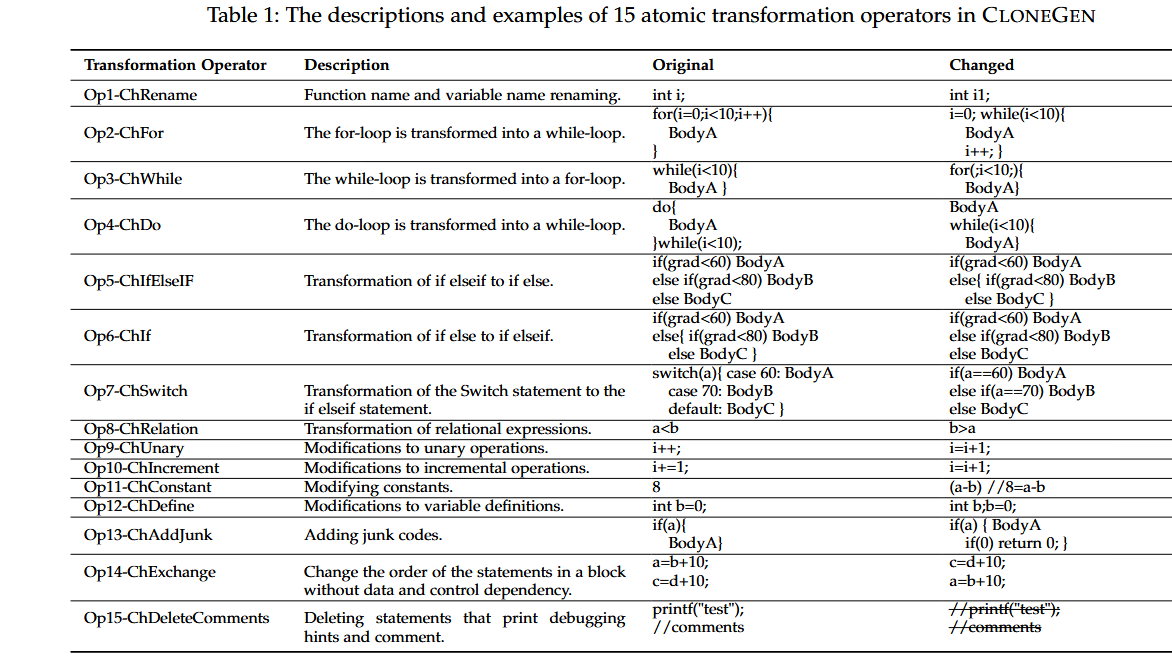
本文设计了15个语义保留的代码转换操作,包括:
- 变量重命名:改变变量名(Op1-ChRename)。
- 循环转换:将
for循环转换为while循环(Op2-ChFor)。 - 条件语句转换:将
if-else语句转换为if-else-if(Op5-ChIfElseIF)。
这些操作保证了代码的语义不变,但通过改变代码的语法结构来增加检测的难度。
CLONEGEN中的原子变换算子如下,仅采用TXL中的词法分析:
encoding
编码是在代码转换之前用来提取标识符特征的
作者使用代码的特征向量进作为编码方案,通过计算代码的特征向量长度,CLONEGEN可以为每个特征分配一个位置,之后通过位向量(bit vector)来指示哪些特征可以被转换操作影响。
$l_b=\sum(n_v,n_f,n_w,n_{do},n_{nie},n_i,n_s,n_r,n_u,n_{sc},n_c,n_d,n_b,n_{is},n_p)(1)$
图一#1编码示例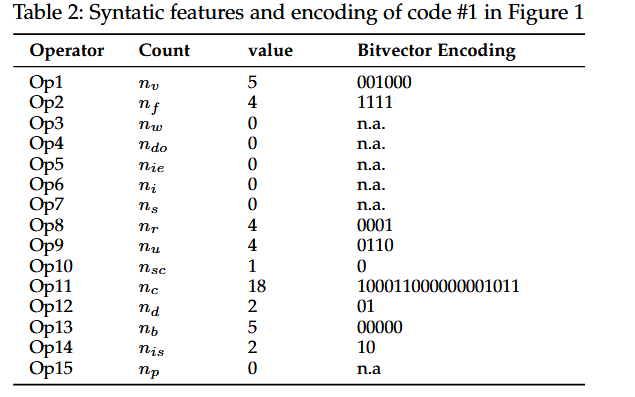
位向量的长度等于第二列的特征计数,,其中原子操作会起作用的特征置为1,否则为0。符号’ n.a . ‘表示没有与对应原子操作相匹配的可用特征,特征计数必须为0。
代码转换策略
将寻找应用原子操作的最优序列的搜索问题看作是一个组合优化问题。作者使用了随机搜索RS,遗传算法RA和马尔可夫链蒙特卡罗MCMC。RS是完全随机的进行01赋值,RA目的是找到最大的编辑距离,即文本相差最大的代码,MCMC使用n - gram算法来计算概率,以确定子序列遵循其前缀的可能性,同样采用困惑度指标来衡量代码发生的概率大小,k-gram的定义:
$H_{\mathcal{M}}(s)=-\frac1n\sum_1^n\log p_{\mathcal{M}}\left(s_i\mid s_{i-k+1}\cdots s_{i-1}\right)\text{(Perplexity)}$ 根据上述公式,该策略通过多次迭代指导代码转换,并输出满足上述困惑度条件的生成克隆。MCMC策略倾向于生成难以理解的(具有高度的复杂性)的语义克隆
DRLSG策略
尽管以上三种策略总体上是有效的,但它们都没有考虑反馈,为了解决这一缺点,作者提出了DRLSG。
在深度强化学习中,Agent:学习者和决策者的角色。环境:一切由Agent以外的事物构成并与之相互作用的事物。动作:agent body的行为表征。状态:有能力的主体从环境中获得的信息。奖励:来自环境对行动的反馈。Strategy:Agent基于状态执行下一步动作的函数;on-policy:Agent学习时和Agent与环境交互时对应的策略相同;off-policy:Agent学习时和Agent与环境交互时对应的策略不相同。
在强化学习中,policy表示在给定的状态下应该采取什么行动,用π表示,在DRL中π是一个神经网络,用θ来表示π的参数,再取境输出状态( s )和智能体输出动作( a ),把s和a串在一起,称为一条轨迹( τ ) τ = {s1, a1, s2, a2, · · · , st, at}。每条轨迹发生的概率为:$p_\theta(\tau)=p\left(s_1\right)\prod_{t=1}^Tp_\theta\left(a_t\mid s_t\right)p\left(s_{t+1}\mid s_t,a_t\right)\quad\quad(2)$ 奖励函数根据在某一状态下采取的某一行动,决定现在有多少个点可供该行动使用。我们要做的是调整行动者内部的参数θ让$\bar{R}{\theta}=\sum{\tau}R(\tau)p_{\theta}(\tau)$ 尽可能大,为了尽可能的大,作者使用了梯度上升
$\begin{aligned}\theta&\leftarrow\theta+\eta\nabla\bar{R}_\theta&&(3)\\nabla\bar{R}\theta&=E{\tau\sim p_\theta(\tau)}\left[R(\tau)\nabla\log p_\theta(\tau)\right]&&(4)\end{aligned}$ 近似策略优化( PPO )是策略梯度的一种变体。利用$π_\theta$ 进行数据采集,当$\theta$ 更新时会重新采样训练数据
$\nabla\bar{R}\theta=E{\tau\sim p_{\theta^{\prime}}(\tau)}\left[\frac{p_{\theta}(\tau)}{p_{\theta^{\prime}}(\tau)}R(\tau)\nabla\log p_{\theta}(\tau)\right]\quad\mathrm{(5)}$
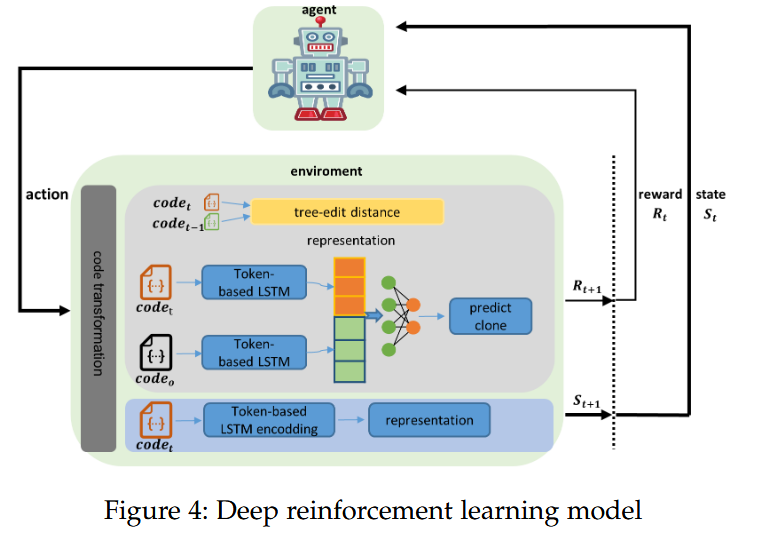
DRLSG主要包括两个组件,agent和environment。agent是一个神经网络,选用$PPO^2$ ,输入是代码的编码向量,称为state。
agent会从给定状态的动作空间中选择要执行的动作。作者使用上述设计的15个变换作为模型的动作空间。
激励函数指导agent的action。算法如下:
奖励有两个主要组成部分,分别是当前动作得到$code_t$和$code_{t - 1}$ 之间的编辑距离,以及当前动作得到$code_t和code_o$ 之间的克隆检测结果。使用biLSTM判断两段代码是否是克隆的,如果不是则获得最大激励(line1-3),中止当前学习,说明得到了当前代码的变换序列。
基于文本序列的基于编辑距离的代码文本相似度CodeTextSim ( codeTextSim ),定义如下
$codeTextSim=1-\frac{editDistance(code_t,code_{t-1})}{max(len(code_t),len(code_{t-1}))}$ 算法的4-6行基于这个公式进行激励函数的负反馈,line7-10行是在控制代码的复杂度。
当前状态是由当前动作的转换代码代表示的,如图4.
Part7. Experiment
数据集
本文使用OJClone数据集进行实验,OJClone包含104个文件夹,每个文件夹中包含500个代码克隆解决方案。通过将这些原始代码克隆对进行转换,生成了不同的测试数据集:DRS、DGA、DMCMC、DDRL。
实验设计
本文将生成的代码克隆对提供给三种机器学习模型进行评估:
- TEXTLSTM:基于文本的克隆检测模型。
- ASTNN:基于抽象语法树(AST)的神经网络模型。
- TBCCD:基于AST和代码标记的卷积神经网络模型。
通过对比不同生成策略(RS、GA、MCMC、DRLSG)对检测器的影响,实验结果表明,DRLSG策略最为有效,能够生成最难被检测的代码克隆。
RQ1的实验表明,CLONEGEN生成的码对可以有效地绕过最先进的ML检测器的检测,TEXTLSTM是最高效的,也是最脆弱的,F1值只有0.421,TBCCD对CLONEGEN的鲁棒性最好,但它依赖于非常昂贵的预处理和训练。最后,ASTNN似乎在效率和鲁棒性之间取得了平衡,因为克隆检测只是ASTNN支持的应用之一。
RQ2的实验表明,使用CLONEGEN的样本进行对抗训练后,基于ML的克隆检测器的F1值显著提高,表明对抗训练增强了基于ML的克隆检测器的鲁棒性。同时,DRLSG策略在生成不可检测克隆方面表现出了最佳的有效性,因为它使得TEXTLSTM,ASTNN和TBCCD在四种策略中达到了最低的准确性。
Part8. Discussion & Future Work
讨论
实验结果表明,当前的基于机器学习的克隆检测器在面对通过语义保留转换生成的克隆时,表现出较低的鲁棒性。尤其是TEXTLSTM,作为一个基于文本的模型,容易被简单的代码变换所欺骗。而TBCCD和ASTNN虽然在鲁棒性上有所提高,但依然未能达到理想的检测精度。

作者表明,基于token的检测是最容易受到影响的,可以轻易的逃避其检测;基于AST的检测器比它好一点,但是,AST结构对操作(如Op2到Op14 )所做的控制或数据流变化不具有弹性。因此,基于AST的检测器擅长检测I型和II型克隆。相比之下,基于CFG或PDG的检测器对控制流或数据流的变化具有更强的适应性,特别是基于CFG的。
未来工作
未来的研究可以集中在改进基于机器学习的克隆检测器,提升它们对语义克隆的检测能力。此外,可以探索更多的代码转换操作和优化策略,以进一步挑战现有的克隆检测技术。同时,强化学习策略也可以在其他软件工程任务中得到应用,提升整体系统的鲁棒性和准确性。
以上是根据论文内容生成的详细阅读笔记,涵盖了方法、实验、结果等重要部分。如需更深入的讨论或进一步分析,请随时告知。



