The Devil is in the Tails: How Long-Tailed Code Distributions Impact Large Language Models
Part1. title&Source
Title: The Devil is in the Tails: How Long-Tailed Code Distributions Impact Large Language Models
Authors: Xin Zhou, Kisub Kim, Bowen Xu, Jiakun Liu, DongGyun Han, David Lo
Source: arXiv (Published 2023)
Part2. abstract
本文探讨了软件工程数据中的长尾分布对大语言模型的影响。研究发现,SE数据通常遵循长尾分布,即少数类别拥有大量样本,而大多数类别的样本很少。本文分析了三项SE任务,揭示了长尾分布对LLMs性能的显著影响。实验结果表明,与频繁标签数据相比,LLMs在不常见标签数据上的性能下降了30.0%到254.0%。研究还提供了应对长尾分布的潜在解决方案,并提出了对未来SE自动化的见解。
Part3. introduction
强调了数据分布在机器学习中的重要性,尤其是在代码分析的任务中,而一些具体的tokens比如apis、libraries或者工具可能大量的出现。现有的研究主要集中在改进模型设计,但本文发现数据集的长尾分布也对模型表现有显著影响。长尾分布意味着少数类别有大量样本,而多数类别的样本极少。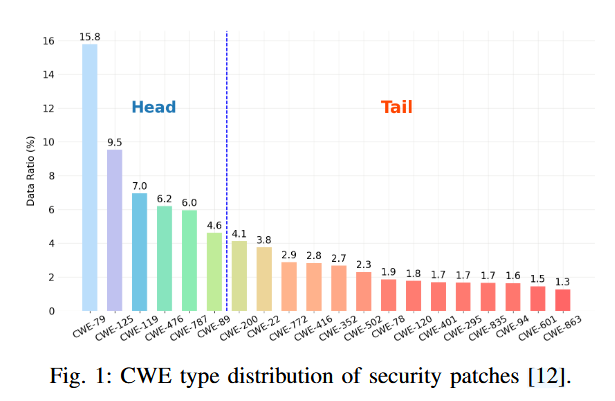
前6个漏洞包含了50%的样例,但是这并不能表名后面的漏洞危害不大。
本文研究了SE任务中的长尾分布如何影响LLMs的性能,特别是在代码生成和分类任务中。通过分析三项具体任务,作者进一步探讨了该分布如何导致模型在处理不常见标签时表现较差。
Part4. conclusion
本文通过研究长尾分布对SE任务中LLMs的影响,得出了以下结论:
- 长尾分布广泛存在于SE数据集,且严重影响模型在尾部数据上的表现。
- 现有模型在尾部数据上的表现比头部数据差30.0%至254.0%。
- 针对长尾分布的现有解决方案(如Focal Loss和LRT)在SE任务中效果有限,改善幅度仅为0.3%到1.4%。
- 未来的研究需要关注如何更好地处理SE数据中的长尾问题,特别是考虑标签之间的关系以改进尾部数据的学习效果。
Part5. related work
相关工作涵盖了长尾分布在商业、统计和计算机科学中的不同定义和应用。在商业领域,长尾分布主要用于理论分析,而在计算机科学中,长尾分布更多地指代偏斜分布。作者还提到了代码中的类不平衡问题以及之前关于代码自然性的研究。此外,作者讨论了在SE任务中长尾现象的观察,例如Java项目规模的分布和软件工件的流行度分布,但之前的研究并未深入分析其对LLMs的影响。
Part6. model & methodology
方法
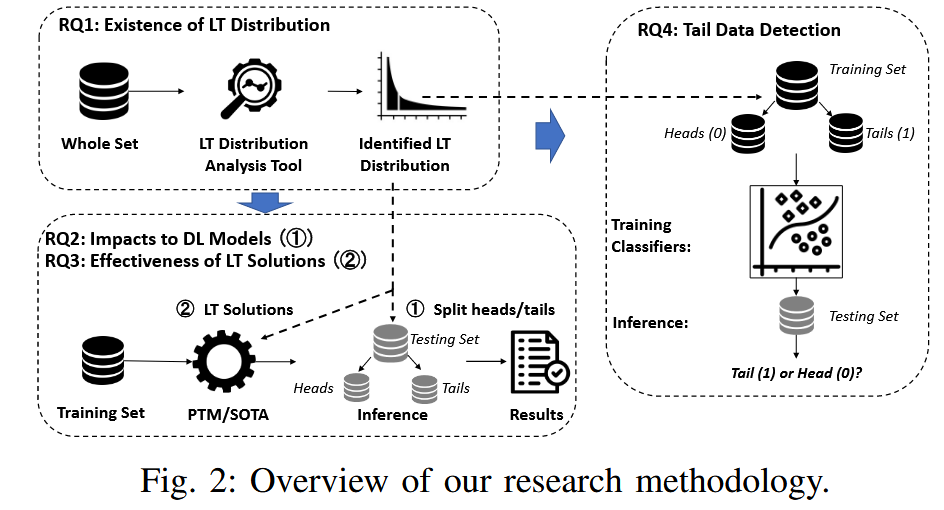
RQ1:To what extent do long-tailed distributions exist in the studied SE datasets
软工领域长尾分布的存在和范围还没有被研究,作者基于此提出了长尾分布分析工具LTAnalyzer,并在三个下游任务中进行了验证
RQ2:How do the long-tailed distributions affect the effectiveness of learning-based SE techniques
重点关注两种流行的代码 LLM(CodeBERT 和 CodeT5)和三种研究任务的最新方法。
RQ3:How effective are the potential solutions to address long-tailed distributions for SE tasks
作者研究了计算机视觉中的两种技术(Focal Loss 和 LRT )在长尾 SE 数据集上的有效性。Focal Loss 是一种广泛使用的解决方案,用于减轻长尾分布的影响。LRT 是计算机视觉领域最先进的缓解解决方案
RQ4:How accurately can we identify the tail
在推理过程中识别尾部数据对于警告用户预测标签的可靠性非常重要。因此,研究问题旨在研究如何使用微调的 CodeBERT 模型准确地分类测试数据实例是属于头部还是后端。
使用了3个下游任务,包括两个生成式任务和一个分类任务。
模型
本文研究了两类模型:
- 主流的LLMs:包括CodeBERT和CodeT5,这些模型在API序列推荐、代码修订推荐和漏洞类型预测等任务中表现出色。
- 最先进的任务特定模型:包括MulaRec(API序列推荐任务)、T5-Review(代码修订推荐任务)和TreeVul(漏洞类型预测任务)
LTAnalyzer
为了量化长尾分布对模型性能的影响,作者设计了一个名为LTAnalyzer的工具来分析数据集的长尾分布,并在模型头部和尾部数据上分别进行性能评估。
该工具将任务的标记数据集作为输入并输出长尾的程度,主要功能是帮助研究人员分析数据集中的标签分布,并评估长尾分布的严重程度。
分析步骤如下:
- 标识生成任务的唯一标签
分析数据分布时LTAnalyzer 首先对分类任务和生成任务进行区分
- 分类任务:对于分类任务,标签通常是互斥的,即每个数据样本只能属于一个标签。LTAnalyzer 可以直接识别这些标签,并分析它们的分布。
- 生成任务:生成任务中的标签并不直接以类的形式出现,而是通过生成的序列(例如API调用序列或代码修改序列)表现出来。因此,LTAnalyzer 针对生成任务的特定需求,定义了独特的标签形式。例如,对于API序列推荐任务,API是最细粒度的单位,因此被定义为标签;而在代码修订推荐任务中,标签则被定义为代码的具体修改操作(token-level edits)。
- 量化长尾分布:LTAnalyzer 使用 Gini 系数 来量化数据集的长尾程度,从而帮助研究人员明确长尾分布对数据集的影响。
$Gini=\frac{\sum_{i=1}^n\sum_{j=1}^n|x_i-x_j|}{2n^2\bar{x}}$
xi 表示标签 iii 所对应的样本数量;
n 是数据集中标签的总数;
$\bar{x}$
是所有标签样本数的平均值
Gini 系数为 0% 时,表示完美均等分布,即每个标签都有相同的样本数量;100% 则表示极端不平等分布,即只有一个标签拥有全部样本。
Part7. experiment
RQ1: Extent of LT Distribution
长尾分布图:前 213 个常用 API(在 99,317 个 API 中)占数据样本的一半;尽管每个尾部标签的数据样本较少,但尾部标签中有许多重要的标签。例如,到 2022 年,前 25 种最危险的 CWE 类型中有 14 种属于尾部
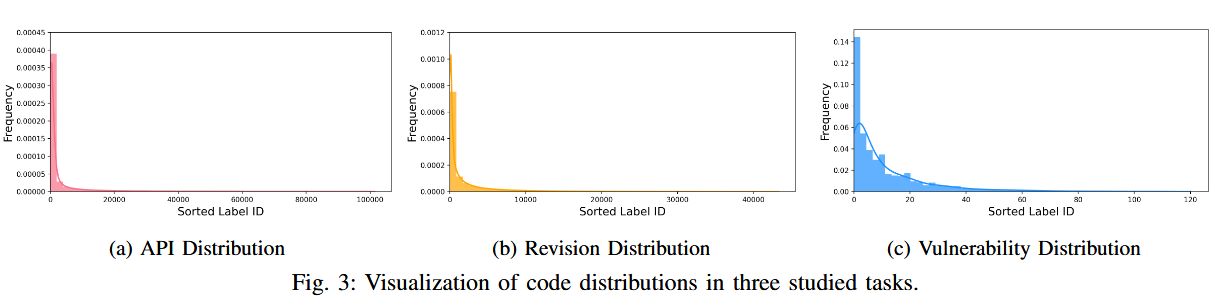
SE数据集比CV领域的长尾数据集的长尾性更高,可能是SE数据集的标签具有唯一性导致的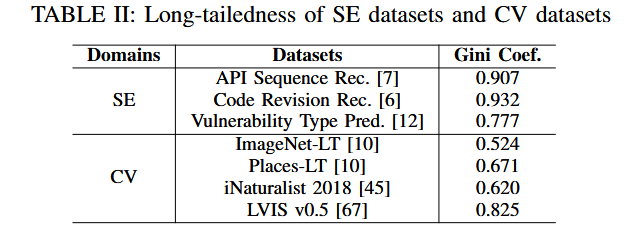
RQ2: Impacts on DL Models
对于生成式任务来说,计算 Ground Truth 序列中标签的倒数频率之和作为序列级分数
$\sum_{x_i\in x_{set}}\frac1{freq(x_i)}$
f req(.) 是标签的频率
$x_{set}$ = [x0, x1, …, xn] 是指 ⟨input, ground truth⟩ 的真值中包含的标签
序列水平得分较高(包含更多不频繁标签)的数据有一半是 tail 数据,其余是 head 数据
重点探讨了长尾分布对模型性能的影响,具体任务包括:
- API序列推荐:MulaRec、CodeBERT和CodeT5在尾部数据上的性能分别比头部数据差30.0%、53.3%和32.7%。
- 代码修订推荐:T5-Review、CodeBERT和CodeT5在尾部数据上的性能差异达到了243.9%、254.0%和203.7%。
- 漏洞类型预测:TreeVul、CodeBERT和CodeT5在尾部数据上的表现分别差43.6%、39.4%和60.9%。
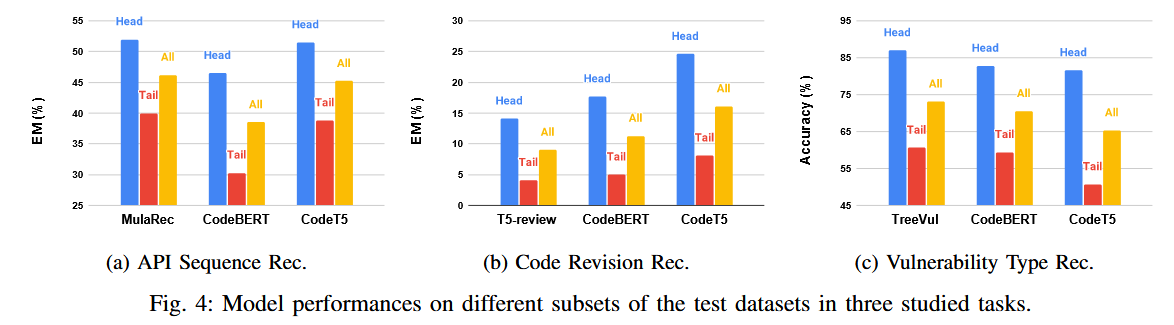
同时,作者在10个小组进行了三个任务的测试,结果表明与另外两个任务不同,漏洞检测任务有一个明显的阶梯模式,更频繁的数据标签(前 40% 的数据),结果更好(准确率为 80-98%),而对于不太频繁的数据标签(最后 60% 的数据),性能显著下降(准确率为 31-73%)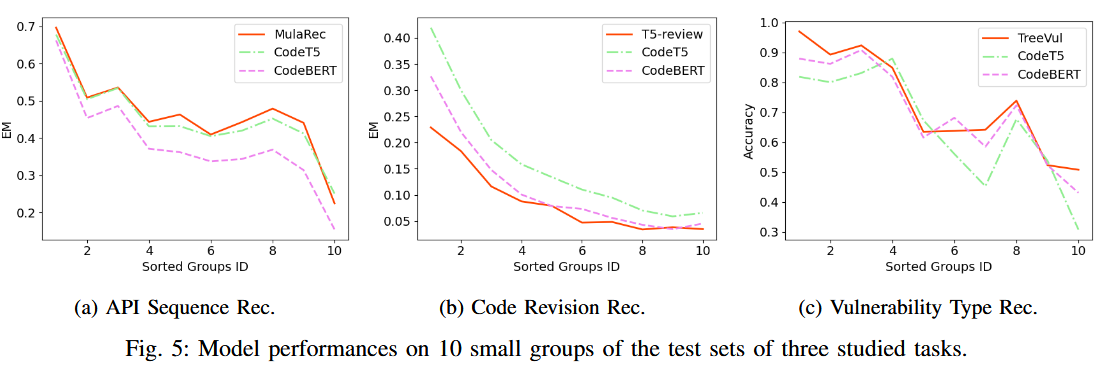
同时,作者还通过量化分析表名长尾分布影响了模型的有效性。在代码修复任务中,比如public(head)和protected(tail),以及在漏洞检测中正确和错误的案例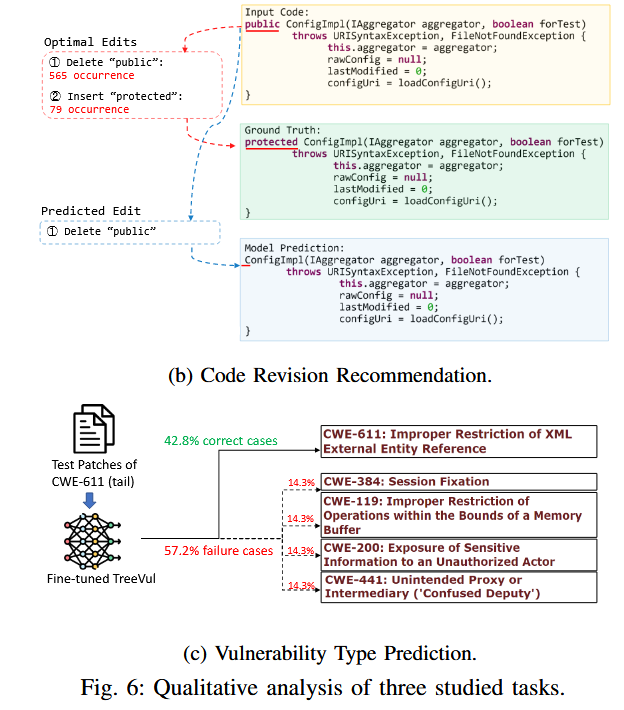
RQ3: Effectiveness of LT Solutions
此外,作者还尝试了Focal Loss和LRT等解决方案,尽管在计算机视觉领域效果较好,但在SE任务中效果不显著,提升仅为0.3%到1.4%。可能是因为这些解决方案将每个标签视为完全不同的标签,而忽略了它们之间的关系。
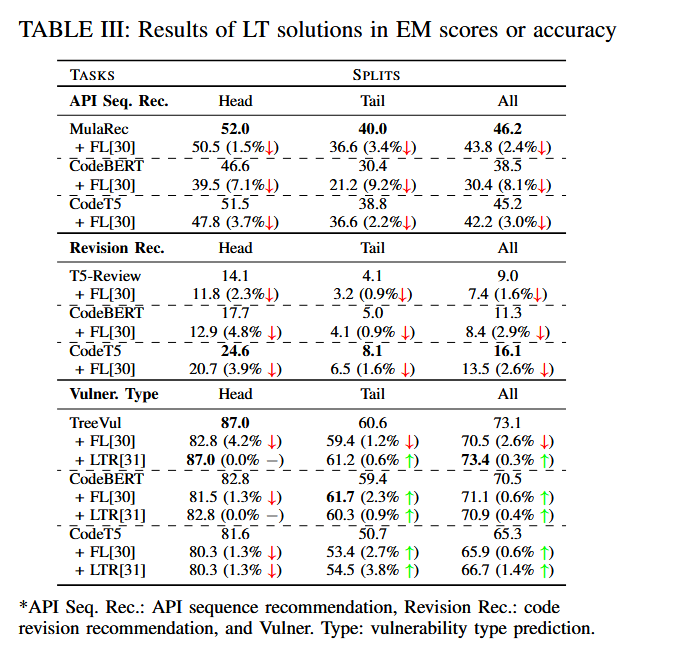
RQ4: Tail Data Detection
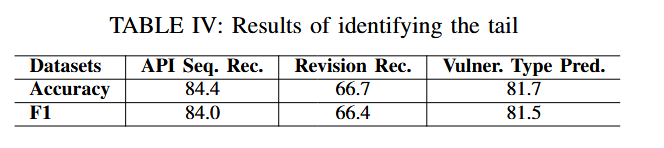
通过微调 CodeBERT 模型来执行二元分类任务,将 tail 视为正类,将 head 视为负类并训练 CodeBERT 以最小化交叉熵损失。实验结果如下,在 API 序列推荐和漏洞类型预测中,对尾部的准确识别 (准确率分别为 84.4% 和 81.7%)。但是,我们的方法在代码修订建议中实现了 66.7% 的较低准确率。这表明识别尾部的难度因任务和关联的数据集而异
尾部检测的潜在应用是建议用户忽略对尾部数据的预测或者强制自动化 SE 工具输出类似“由于缺乏相关知识,我不确定答案”之类的响应
Part8. discussion&future work
作者还讨论了传统的机器学习模型(适用于分类任务)比如逻辑回归 (LR) [75]、决策树 (DT) [76]、支持向量机 (SVM) [77] 和随机森林 (RF)在漏洞类型预测任务上的表现,与llms表现出相同的趋势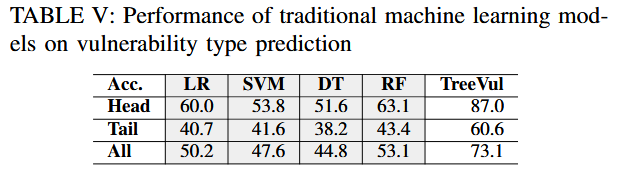
作者也提醒我们需要注意平均结果需要谨慎使用,这种做法无意中掩盖了模型在尾部的缺点,因为它在头部数据上表现得非常好,但在尾部数据上表现不佳。在漏洞类型预测中,有 117 个类别,TreeVul 在大多数类型(107 种尾部类型)上实现了 60.6% 的准确率,但由于 6 种头部类型的准确率很高 (87.0%),平均结果为 73.1%。但是,在此任务中,TreeVul 在大多数 CWE 类型(107 种尾部类型)上无法达到 73.1% 的准确率。
针对软件领域,需要一种定制的方法来有效地学习数据中的尾部。需要考虑丰富的标签关系
others
真值和标签
- 真值(Ground Truth)
真值指的是模型应该预测的正确答案,通常是由人工标注或根据已知的事实得出的。在训练或测试模型时,真值是模型用于比对其预测结果是否正确的标准
API序列推荐任务:真值是指给定代码上下文和自然语言查询后,模型应该生成的正确API调用序列。这个序列是从真实代码中提取出来的。例如:
- 输入:一个Java函数的部分代码和Javadoc描述。
- 真值:该函数接下来应该调用的API序列,如
Reader.read()、System.arraycopy()等。
代码修订推荐任务:真值是根据代码审查者的评论,模型应该生成的修订后的代码版本。这一版本是开发者在真实代码审查过程中对代码进行修改后得到的。例如:
- 输入:原始代码和审查者评论。
- 真值:修订后的代码,如把一个
public方法修改为protected。
漏洞类型预测任务:真值是补丁对应的具体漏洞类型(如CWE类型),这些漏洞类型是由安全专家根据补丁的实际性质标注的。例如:
- 输入:一个安全补丁的代码提交。
- 真值:这个补丁对应的CWE漏洞类型,如
CWE-79(跨站脚本攻击)或CWE-863(不正确的授权)。
- 标签(Labels)
标签通常是指模型在训练过程中所使用的目标类别或目标数据。它们是用于监督学习的关键部分,模型通过学习数据与标签之间的对应关系,来进行预测。
API序列推荐任务:标签是每个API调用的名称。在训练过程中,模型会学习输入代码片段和自然语言描述与对应API调用序列之间的关系。例如,在Java函数的实现中,常见的标签包括
Reader.read、System.arraycopy等API调用。如果函数中使用了这些API,模型需要学会预测这些API。代码修订推荐任务:标签是指代码修订中的具体修改操作,即代码在审查后所做的改动。每个修改操作(如插入某个关键词、删除某个变量)可以看作是一个标签。例如,如果审查者评论要求修改方法的访问权限,那么标签可能是 “删除
public并插入protected“。漏洞类型预测任务:标签是补丁的漏洞类型(CWE类型),这些标签表示模型需要预测补丁所属的具体漏洞类别。例如,一个补丁可能被标注为
CWE-79(跨站脚本攻击),这是模型需要学习的标签
两者关系
真值是实际存在的数据,是模型预测结果的标准答案,而标签是指模型在训练过程中使用的已标注好的类别或输出。在训练过程中,模型通过学习训练数据的输入与标签之间的映射关系,来学会在测试数据上预测与真值相符的标签。
API序列推荐任务:
- 输入:自然语言查询 “Read data from file” 和代码上下文。
- 真值:应该调用的API序列,例如
FileReader.read()和BufferedReader.readLine()。 - 标签:API名称,如
FileReader.read()和BufferedReader.readLine()。
代码修订推荐任务:
- 输入:审查者的评论:”The method should be protected instead of public”。
- 真值:修改后的代码
protected void methodName()。 - 标签:具体修改操作,如 “删除
public并插入protected“。
漏洞类型预测任务:
- 输入:某个安全补丁的代码。
- 真值:对应的漏洞类型为
CWE-79(跨站脚本攻击)。 - 标签:
CWE-79,表示补丁所属的漏洞类别
分割数据集
长尾分布意味着数据集中存在少数频繁出现的标签(头部标签)和大量出现频率低的标签(尾部标签)。这些尾部标签尽管样本少,但往往非常重要。然而,机器学习模型通常倾向于在频繁标签(头部数据)上表现良好,而在不常见的标签(尾部数据)上表现较差。因此,分割数据集并分别评估模型在头部和尾部数据上的表现,可以揭示模型在不同标签分布下的性能差异。
除了将数据集简单地分为头部和尾部数据,作者还进一步将测试集细化为10个小组,每组包含相同数量的样本,但按标签的频率从高到低排序。这种细化分割的目的是为了更精确地分析模型在不同频率标签上的表现,提供更加细致的洞察。
长尾现象在llms中出现的原因
- 自然语言和代码数据的内在分布特性
无论是自然语言数据还是代码数据,它们都天然存在长尾分布。这意味着在这些数据集中,少量的词汇、代码模式或API调用会频繁出现,而大量的其他词汇或代码片段则很少出现。这种不平衡分布是由以下几个原因造成的:
语言的高重复性和模式化。
开发者行为的多样性,不同的开发者和团队可能在相同问题上采用不同的解决方案或风格,这会进一步扩大长尾现象
- 模型训练中的偏差
LLMs的训练过程中,数据分布的偏差会导致模型偏向于学习频繁出现的模式,而忽略那些不常见的模式。这种偏差在以下几个方面体现出来:
- 频繁标签的影响更大,模型在训练过程中,频繁出现的标签(即头部标签)占据了大部分的训练数据,因此它们对模型参数的更新影响更大。随着模型不断优化这些频繁标签的预测能力,它对不常见的标签(即尾部标签)的关注度和学习效果相对较低。长尾现象会导致模型更加“偏向”高频的模式,忽略或学习不足低频的稀有模式
- 损失函数的影响,传统的损失函数(如交叉熵损失)在处理不平衡数据时,倾向于最小化整个数据集上的平均误差,而非对不平衡数据进行加权。这意味着模型更多地关注那些频繁出现的模式,而忽略了稀有模式。
- 稀有标签的学习困难
稀有标签的学习本质上是一个小样本学习(few-shot learning)问题。由于长尾分布中的尾部标签样本数量非常少,模型在训练过程中很难从少量的训练样本中学习到有效的特征。
数据采集偏差:数据集通常是从开源代码库、论坛(如Stack Overflow)、版本控制系统(如GitHub)等来源收集的。在这些数据中,常用的代码库和函数调用会被频繁使用和记录,而那些特殊用途或行业专用的代码库则很少被使用。这导致数据集中某些API调用或代码模式的频率极低
样本不足:对于尾部标签,模型可能只在训练数据中见到过几次甚至一次样本。在这种情况下,模型很难学习到这个标签的正确使用方式或生成模式。这意味着即使模型在测试时遇到这些标签,它也无法正确地进行预测。



