Natural Attack for Pre-trained Models of Code
Part 1. Title & Source
Title: Natural Attack for Pre-trained Models of Code
Authors: Zhou Yang, Jieke Shi, Junda He, David Lo
Source: 44th International Conference on Software Engineering (ICSE ’22), May 21–29, 2022, Pittsburgh, PA, USA
DOI: 10.1145/3510003.3510146
Part 2. Abstract
The paper explores vulnerabilities in pre-trained models of code to adversarial attacks. The authors propose ALERT (Naturalness Aware Attack), a black-box method to adversarially transform inputs, generating more natural adversarial examples than prior methods like MHM. ALERT preserves operational and natural semantics of code, making the examples not only executable but also contextually appropriate for humans. Experiments demonstrate that ALERT outperforms MHM on pre-trained models like CodeBERT and GraphCodeBERT in tasks such as vulnerability prediction, clone detection, and authorship attribution. The robustness of models improves with adversarial fine-tuning using ALERT-generated examples.
Part 3. Introduction
作者提到对抗性代码需要保证自然性,否则所生成的对抗性代码很有可能被人们所拒绝。现有的针对模型的攻击代码是有效的,但是他们更注重的是保留操作的语义而不是对于人类的判断来说该攻击是否能够被识别(比如MHM)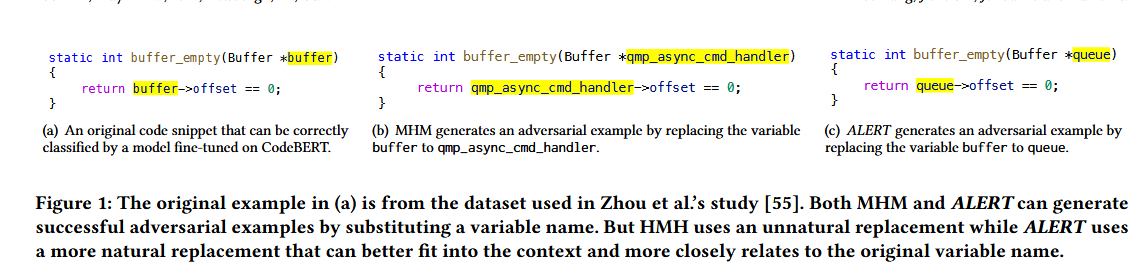
论文介绍了 ALERT,这是一种黑盒对抗性攻击,同MHM一样通过修改变量名生成对抗性样本,它强调操作语义和自然语义,确保生成的示例更容易被人类判断。ALERT首先使用预训练模型中的掩蔽语言预测函数来生成自然替代品,利用上下文信息来预测隐藏令牌的潜在价值。
ALERT首先使用贪婪算法(GreedyAttack),如果贪婪算法失败,则使用遗传算法( GA- Attack ),并在漏洞预测、克隆检测和代码作者归属三个问题上进行了实验。
文章贡献:
- 强调了代码模型生成对抗性样本的自然性,并提出了在生成对抗变量替代物时感知自然语义的ALERT
- 首先开发了针对CodeBERT和GraphCodeBERT的对抗攻击,并表明在最先进的预训练模型上进行微调的模型容易受到此类攻击
- 展示了ALERT生成示例的价值:使用这些对抗示例对受害者模型进行对抗微调,可以使CodeBERT和GraphCodeBERT对抗ALERT的鲁棒性分别提高87.59 %和92.32 %。
Part 4. Conclusion
The paper highlights the importance of naturalness in generating adversarial examples for code models. ALERT, the proposed black-box attack method, achieves high attack success rates across multiple downstream tasks on CodeBERT and GraphCodeBERT, outperforming prior methods like MHM. ALERT’s adversarial examples are more natural and imperceptible to human judges. The paper also demonstrates the value of these adversarial examples in enhancing model robustness through adversarial fine-tuning, which significantly improves the models’ defense against such attacks.
Part 5. Related Work
The paper discusses two primary topics in related work: pre-trained models of code and adversarial attacks on those models. It surveys pre-trained models like CodeBERT and GraphCodeBERT, which have been fine-tuned for various code-related tasks. In the domain of adversarial attacks, prior works like MHM and DAMP are mentioned. MHM is a black-box attack using variable renaming, which ignores the naturalness of variable names, making the adversarial examples less likely to fool human reviewers. Other approaches like DAMP, a white-box attack, leverage gradient information, which is impractical in most real-world scenarios.
Part 6. Model&Methodology
生成naturalness-aware substitutes
ALERT 旨在提高对抗性示例的自然性。核心思想涉及生成变量名称的替换,以维护操作语义(对机器重要)和自然语义(对人类重要)。该方法使用预训练模型的掩码语言建模 (MLM) 和上下文嵌入来创建可能替代的排名列表。
生成单个变量的自然替代通常包含3个操作步骤:
将代码片段转换成CodeBERT或GraphCodeBERT可以作为输入的格式,由于源代码通常包含领域特点缩略词,专业术语等不在语义集合中的词汇,会造成词汇外问题。两个模型都使用字节对编码( Bpe )来解决这个问题,从而生成子token
然后,我们为每个子token生成潜在的替代品。利用CodeBERT或GraphCodeBERT的mlm,生成潜在替代子标记的排序列表,并选择top - j的替代品
接下来,将原始序列T中的子令牌替换为步骤2中生成的候选子令牌$T^{\prime}$,预训练模型计算每个$T^{\prime}$的上下文嵌入,与T中计算$t_i^{\prime},t_{i+1}^{\prime}$中的相似。余弦相似度被用作度量候选token序列与原始变量的子token序列在多大程度上相似,并采用top - k将其还原成具体的变量名
具体的生成算法如下

最后return的subs即为naturalness-aware substitutes
Greedy-Attack & GA-Attack
ALERT 采用两步搜索过程,首先是greedy-attack
1.Greedy-Attack:这种启发式方法首先计算代码片段中每个变量的重要性得分,并首先替换最重要的变量。它根据它们如何降低模型的置信度来选择最佳的对抗性示例。
- 全局重要性评分 Overall Importance Score”(mertic)
为了通过重命名变量来执行语义保持转换,攻击者首先需要决定代码片段中哪些令牌应该被更改。
代码片断c中第i个令牌的重要性评分定义如下:
$IS_i=M(c)[y]-M(c_{-i}^*)[y]$
其中
Y为c的真值标签,$M(c)[y]$表示标签y对应的m的输出的置信度
通过将c中的第i个token (必须是一个变量名称)替换为<unk>,从而创建了一个变体$c_{-i}^*$ ,这意味着在该位置处的字面值是未知的
重要性评分近似表示知道第i个令牌的值如何影响模型对c的预测,$IS_i$ 大于0,表示第i个token可以帮助模型正确预测c
为什么要用OIS呢?
因为一个变量可能出现在一段代码的多个位置,而变量的替换需要考虑该变量出现的所有位置
OIS的计算:
$OIS_{var}=\sum_{i\in var[pos]}IS_i$
var是c中的一个变量,var [ pos ]是指var在c中的所有出现。
OIS可以看作是白盒攻击中梯度信息的类比
- Word Replacement
基于OIS的贪心算法来生成对抗性样本

2.GA-Attack: Greedy-attack可能会遇到单一局部最优,如果贪婪攻击无法找到对抗性示例,ALERT 将应用遗传算法进行更详尽的搜索,结合突变和交叉来探索不同的替换。

算法的解释如下:
Chromosome Representation:在GA中,染色体代表目标问题的解,染色体由一组基因组成,本文中,每个基因都是一对原始变量及其代换。假设一个输入程序中只能替换两个变量( a和b),染色体<a:x,b:y>表示将a替换为x,b替换为y。
Population Initialization:在GA的运行过程中,种群(一组染色体)进化以解决目标问题。GA-Attack维护一个种群,其规模为可替代的提取变量的数量,它可以利用上一个步骤的信息。GA-Attack可以只改变一个变量,保持其他变量不变。
- 例如,假设从输入程序中提取3个变量( a、b、c),Greedy - Attack建议<a:x,b:y,c:z>,GA - Attack初始化3条染色体的种群:<a:x,b:b,c:c>,<a:a,b:y,c:c>,<a:a,b:b,c:z>
Poerators:Greedy-Attack有多次迭代,在每次迭代中,使用两个遗传算子(变异和交叉)来产生新的染色体。算法3以r的概率进行交叉,以1 - r的概率进行变异(line6-9)。
具体的:首先随机选择一个截止位置h,将位置h后的c1基因替换为对应位置的c2基因。eg:对于两条染色体( c1=<a : x , b : y , c : c>和c2 =<a : x , b : b , c : z>和一个截断位置h = 2,
交叉产生的子代<a:x,b:y,c:z>。
变异算子随机选择一个基因,然后用随机选择的替代品替换该基因。例如,⟨中的<a:x,b:b>被选中,a:x变成a:aa
- Fitness Function:较高的适应度值表明染色体(变量的替换)更接近该问题的目标(line14)
算法计算受害者模型关于原始输入和变量上的真实标签的置信值。将置信度值之间的差值作为适应度值。
假设T是原始输入,$T^{\prime}$ 是对应于一条染色体的变体:
$fitness=M(T)[y]-M(T’)[y]$
GA - Attack始终保持相同大小的种群(提取变量的个数)。它丢弃了适应度值较低的染色体(替代的变量)
上述两种方法都旨在最大限度地减少变量变化的数量,同时最大限度地提高对模型预测的影响。
Part 7. Experiment
Datasets and Tasks
实验使用了三个下游任务及其对应的数据集

Vulnerability Prediction’s benchmark:CodeXGLUE
Clone Detection’s benchmark:BigCloneBench
Authorship Attribution’s benchmark:Google Code Jam (GCJ)
Result And Analysis
Research Question:
RQ1:How natural are the adversarial examples generated by ALERT

Answers to RQ1:参与者一致发现ALERT (一种自然感知的方法)生成的对抗样本是自然的,而MHM (一种自然-不可知论的方法)生成的对抗样本是非自然的。
**RQ2:**How successful and minimal are the generated adversarial examples? How scalable is the generation process?
Key metrics used:
- Attack Success Rate (ASR): The percentage of examples where the attack caused the model to produce incorrect results.

- Variable Change Rate (VCR): The proportion of variables changed in the code snippet.
- Number of Queries (NoQ): The number of times the victim model is queried during the attack.
Answers to RQ2:从攻击成功率来看,在3个下游任务上,ALERT比MHM在CodeBERT上分别提高了17.96 %、7.74 %和16.51 %,在GraphCodeBERT上分别提高了21.78 %、4.54 %和29.36 %。除了取得了优越的攻击成功率外,ALERT还做了更少的修改,更具有可扩展性
RQ3:Can we use adversarial examples to harden the victim models?

Answers to RQ3:ALERT生成的对抗样本在提高受害者模型的鲁棒性方面是有价值的。使用ALERT生成的对抗样本对受害者模型进行对抗微调,可以使CodeBERT和GraphCodeBERT的准确率分别提高87.59 %和92.32 %
Part 8. Discussion & Future Work
other black box Attack
- Pour et al. 提出的测试框架,针对代码模型的测试框架,通过修改代码中的局部变量名来评估模型的鲁棒性。虽然该框架能够有效地测试模型的稳健性,但其攻击成功率相对较低
- Rabin et al. 的变量重命名方法,通过修改代码中的变量名来生成对抗样本,测试模型的鲁棒性。该方法针对神经网络模型(如 GGNN),通过局部变量名的改变测试模型的泛化能力。
作者讨论了他们工作的更广泛的影响,并指出虽然 ALERT 改进了代码模型的对抗性攻击,但仍有进一步研究的空间。例如,扩展方法来处理更多样化的编程语言和更大规模的模型可能是有益的。此外,他们建议探索其他方法将自然性与对抗鲁棒性结合起来,有可能整合对代码结构更深入的语义理解。未来的工作还可能着眼于改进遗传算法,以更好地优化对抗性示例,并将 ALERT 应用于软件工程中的其他任务,例如错误修复或补丁生成



