Code Security Vulnerability Repair Using Reinforcement Learning with Large Language Models
Part 1: 标题 & 作者
标题: 基于强化学习和大规模语言模型的代码安全漏洞修复
作者: Nafis Tanveer Islam, Mohammad Bahrami Karkevandi, Peyman Najafirad
机构: 德克萨斯大学圣安东尼奥分校,安全人工智能与自主实验室,计算机科学系
Part 2: 摘要
随着大规模语言模型(LLMs)的快速发展,开发人员可以更轻松地生成功能性正确的代码。然而,使用LLMs生成的代码也伴随着重大的安全风险。在生成功能性代码的过程中,确保代码安全性是一项比生成功能性代码更具挑战性的任务。目前的代码修复模型通常依赖于监督微调,并通过最小化交叉熵损失来生成修复代码,但由于修复代码与原代码功能相似,仅在少数行代码上有所改动,常常忽略安全措施。本文提出了一种基于强化学习的程序修复方法,结合语法和语义奖励机制,着重在生成功能性代码的同时,增加必要的安全措施,从而提高代码的安全性。
Part 3: 引言
软件漏洞是系统中的一组潜在缺陷或弱点,攻击者可以利用这些漏洞访问系统、停止系统服务,甚至对软件供应商进行勒索。当威胁者通过恶意手段窃取机密信息或造成经济损失时,情况变得更加严峻。开源软件的广泛使用加剧了这种风险,安全漏洞会对政府和关键基础设施造成重大影响。当前,开发人员越来越多地使用大规模语言模型生成代码,这些模型虽然提升了代码的生产力和功能性,但往往忽略了安全标准,导致生成的代码在约40%的情况下存在漏洞。
为了解决以上问题,作者提出基于强化学习( RL )的技术来修复源代码的漏洞,并设计了专门用于增强代码安全性的激励函数。同时设置了句法激励机制,即只有在代码中添加适当的安全措施才能对RL模型进行奖励。为了保证我系统在功能上的正确性,作者还提出了句法和语义结合的激励函数为漏洞代码生成安全性修复
本文的主要贡献:
- 介绍了一个LLMs驱动功的工具修复c/c++漏洞代码,该工具利用RL生成安全性代码,同时保持了代码功能
- 引入了句法和语义奖励值的组合,以增强我们提出的强化学习模型生成安全和功能代码的能力
- 对模型成果的定量分析
Part 4: 结论
作者提出了基于强化学习的CodeRepair来确保代码修复过程中的功能性和安全性;并且提出了语法和语义结合的激励机制CodeBLUE和BERTScore来确保功能和语义的正确性
Part 5: 相关工作
与代码生成和修复相关的工作主要分为两个方面。首先,大规模语言模型生成的代码通常缺乏对安全漏洞的有效修复。现有的研究表明,这些模型可以生成功能正确的代码,但在涉及安全漏洞修复时表现不佳。部分工作探索了如何引导模型生成更加安全的代码,例如通过零样本学习或对模型进行进一步优化。其次,程序漏洞修复的传统方法包括利用人类定义的安全属性来修复代码漏洞,或者通过机器学习技术识别漏洞位置并生成修复代码。近年来,基于大规模语言模型的修复方法逐渐成为主流,如VulRepair、CodeT5等。
Part 6: 模型&方法
背景:
代码生成模型的主要挑战是代码中存在的长范围依赖让模型难以决定在哪里添加安全性代码。常规的encoder-decoder架构模型有双向的特性,会导致与漏洞修复无关的计算,因为漏洞推理总是在代码报错之前。
模型:
为了解决这些问题看,作者使用casual-decoder架构模型CodeGen2,它没有encoder层,所以推理时间更快,占用内存更少。模型架构如下
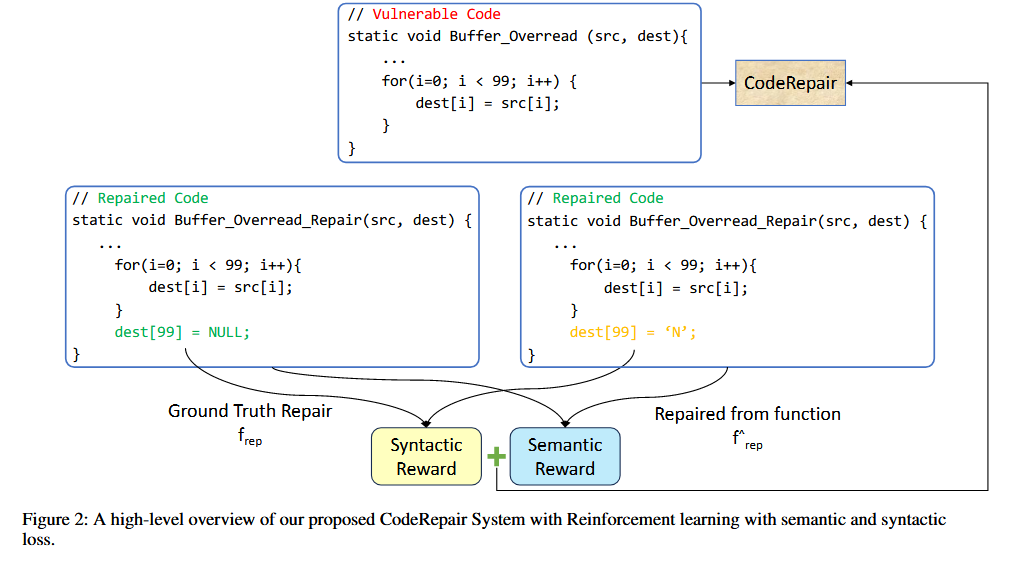
强化学习使用的算法是Proximal Policy Optimization (PPO),目标是最大化修复代码的奖励,这个奖励由两个部分组成:语法奖励和语义奖励
激励机制:
为了确保修复代码在语法和语义上与正确代码保持一致,本文提出了两个主要的奖励机制:CodeBLEU 用于语法匹配,BERTScore 用于语义匹配
- CodeBLEU :结合了标准的BLEU分数和代码特定的语法特征(AST和data flow)
$R_{\text{CodeB}}=\alpha\cdot B+\beta\cdot B_{\text{weight}}+\delta\cdot\text{Match}{\text{ast}}+\gamma\cdot\text{Match}{\text{df}}$
B代表BLEU分数,即n-gram的匹配程度。
$B_{\text{weight}}$是 加权的n-gram匹配,用来衡量代码修复后与真实修复代码的匹配程度。
$\text{Match}_{\text{ast}}$ 表示抽象语法树的匹配,用于捕捉代码中的语法信息。
$\text{Match}_{\text{df}}$ 表示数据流的匹配,用来评估生成代码和真实代码的数据流相似度
- BERTScore :评估生成代码与真实修复代码之间的语义相似性。通过将代码中的每个token表示为BERT向量,并计算余弦相似度来量化语义匹配
$R_{\mathrm{BERT}}=\frac{1}{|t_{\mathrm{ir}}|}\sum_{t_{\mathrm{ir}}\in T}\max(t_{\mathrm{ir}})^T\hat{w}_i^r$
$t_{ir}$ 是真实修复代码中的一个参考令牌。
$\hat{w}_{i}^{r}$ 是生成修复代码中的一个候选令牌。
两者通过余弦相似度 $(t_{\mathrm{ir}})^T\hat{w}_i^r$ 进行匹配。
- 最终奖励计算:通过语法奖励和语义奖励的加权组合,值越高代表越理想
$R=R_{\text{CodeB}}+R_{\text{BERT}}$
优化策略
强化学习目标是找到最优策略 $\pi$ ,使得生成代码的累计语法和语义奖励最大化
$L(r_\theta)=\log(\sigma(r_\theta(f_\mathrm{vul},f_\mathrm{rep})-r_\theta(f_\mathrm{vul},\hat{f_\mathrm{rep}})))$
$\bullet$ $r_\theta ( f_\mathrm{vul}, f_\mathrm{rep})$ 是真实修复代码的奖励。
$r_{\theta }( f_{\mathrm{vul}}, \hat{f_{\mathrm{rep}}} )$ 是生成的修复代码的奖励。
$\sigma$ 是激活函数,用来确保生成的修复代码能够尽可能接近真实修复代码。
Part 7: 实验
使用的是VulDeeLocator数据集,
评价指标:
实验使用BLEU Score和Rouge-L作为指标
BLEU用于评估生成的代码与真实修复代码的相似度,它计算n-gram的匹配程度,并通过加权n-gram精度和简短惩罚来获得最终得分
Rouge-L用于评估生成代码与真实修复代码的最长公共子序列(LCS),Rouge-L考虑了生成代码和参考代码的精度和召回率,用于衡量两者之间的相似性。
结果分析:
随着模型参数规模的增加,模型的表现有所提升。1B、3.7B和7B三个不同规模模型的BLEU和Rouge-L得分,具体如下表所示
Part 8: 讨论与未来工作
实验结果表明,本文提出的强化学习模型能够有效地生成安全且功能性正确的代码修复版本。尤其在需要添加安全措施时,强化学习模型表现出更高的效率。未来的工作将专注于改进代码评估方法,尤其是在安全性评价方面,现有的BLEU和Rouge-L分数只关注代码的语法和语义匹配,无法全面反映安全性的改善。因此,开发更合适的评价指标,以同时考虑代码的功能性和安全性,将是未来的重要研究方向。此外,未来研究还将探索如何让模型在面对不同编程语言和更多类型的安全漏洞时,具有更强的泛化能力。



