ChatGPT for Vulnerability Detection, Classification, and Repair: How Far Are We?
Part 1. Title & Source
Title: ChatGPT for Vulnerability Detection, Classification, and Repair: How Far Are We?
Authors: Michael Fu, Chakkrit (Kla) Tantithamthavorn, Van Nguyen, Trung Le
Institution: Monash University
Source: arXiv preprint arXiv:2310.09810 (2023)
Part 2. Abstract
本文旨在评估ChatGPT在四个常见软件漏洞任务中的表现:函数和行级漏洞预测、漏洞分类、严重性估计以及漏洞修复。研究表明,尽管ChatGPT的规模远远超过专为软件漏洞任务设计的语言模型(例如CodeBERT),但其表现显著落后,尤其是在漏洞修复任务上完全失败。实验结果表明,ChatGPT仍需特定领域的微调才能有效地完成这些任务。
Part 3. Introduction
近年来,软件漏洞任务(如漏洞检测、分类、修复等)已成为研究重点。特别是,大规模语言模型(LLMs),如ChatGPT,在代码生成、审查等任务中表现出色,但尚未有系统研究其在软件漏洞任务中的表现。本文通过实证研究,比较了ChatGPT(gpt-3.5-turbo和gpt-4)与现有专门用于软件漏洞的模型(如CodeBERT、GraphCodeBERT等)的表现。研究涵盖190,000多个C/C++函数,回答以下四个研究问题:
- ChatGPT在函数和行级漏洞预测上的表现如何?
- ChatGPT在漏洞类型分类上的表现如何?
- ChatGPT在漏洞严重性估计上的表现如何?
- ChatGPT在自动漏洞修复上的表现如何?
实验结果揭示了ChatGPT的局限性,并强调微调对其在软件安全任务中的必要性。
Part 4. Conclusion
本文首次全面评估了ChatGPT在四个常见软件漏洞任务上的表现,发现其在所有任务中的表现都逊色于经过微调的专用语言模型。特别是,在漏洞修复任务上,ChatGPT未能生成任何正确的修复补丁。这表明,尽管ChatGPT拥有庞大的参数规模和丰富的预训练数据,但其在软件漏洞预测任务中无法有效泛化,仍需进一步的微调以弥补其对安全领域特定知识的缺乏。
Part 5. Related Work
现有研究主要集中在专门设计的语言模型用于软件漏洞预测、分类和修复。例如,AIBugHunter和CodeBERT等模型通过预训练和微调,在漏洞检测和修复任务中表现出色。与之相比,ChatGPT的研究尚处于起步阶段。之前的工作主要测试了ChatGPT在漏洞预测和一般程序修复任务中的表现,本文则扩展了这一工作,评估了其在全流程漏洞任务中的适用性。
Part 6. Model&Methodology
ChatGPT的应用主要依赖于提示工程,而不是微调。
作者将的漏洞预测行级的漏洞预测作为二元分类任务并设计了promot
将漏洞分类表述为多类分类任务,漏洞分类任务的promot如下
漏洞严重性估计作为回归任务,并使用CVSS安全评分来标准化漏洞的严重性,promot如下:
将漏洞修复表述为序列到序列的生成任务,其中模型为输入的易受攻击函数生成相应的修复补丁,promot如下:
研究设计了针对不同漏洞任务的具体提示,包括函数和行级漏洞预测、多类别漏洞分类(基于CWE-ID)、漏洞严重性估计(基于CVSS评分),以及自动漏洞修复。在每个任务中,研究者设计了相应的提示模板,例如在漏洞修复任务中,给出三个示例修复补丁作为模型参考。
Part 7. Experiment
实验采用了Big-Vul用于漏洞预测(RQ1)、分类(RQ2)和修复任务(RQ3)。
对于自动漏洞修复 (RQ4),利用了 陈等人预处理的 Big-Vul 和 CVEFixes 数据集实验。
(RQ1) How accurate is ChatGPT for function and line-level vulnerability predictions?
将gpt系列模型同其他3个基线对比
- AIBugHunter:它利用微调的语言模型来执行漏洞预测、分类、严重性估计和修复
- CodeBERT:一种语言模型,最初是为与源代码相关的任务进行预训练的,它使用 Codesearchnet 数据集进行了预训练
- GraphCodeBERT:也是一种语言模型,同样在 Codesearchnet 数据集上进行了预训练,用于执行与源代码相关的任务。值得注意的是,在形成模型的 input时,GraphCodeBERT 除了考虑源代码标记外,还会考虑数据流图
通过F1 测量、精度和召回率评估函数维度性能,表明ChatGPT 未能在函数级别准确预测,漏洞预测任务需要模型学习特定领域的知识(例如,漏洞模式),并且尽管大型语言模型模型的大小很大,但仍然需要对其进行微调。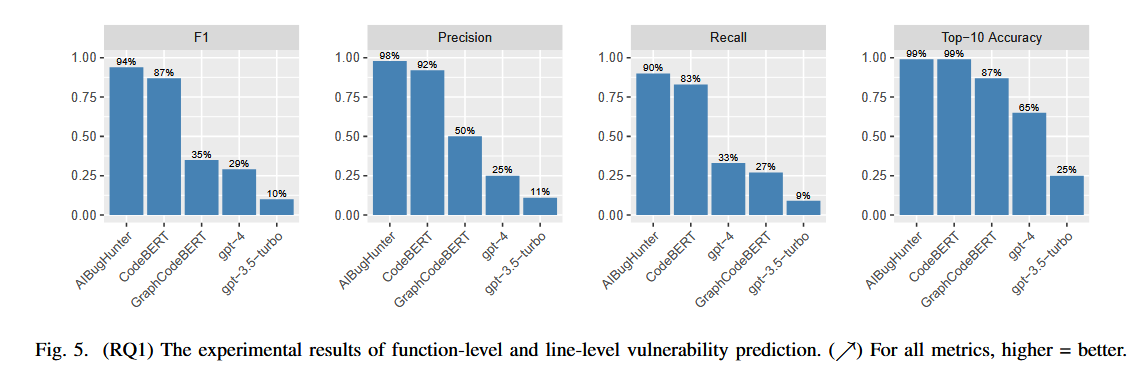
(RQ2) How accurate is ChatGPT for vulnerability types classification?
该实验专注于漏洞分类任务,旨在识别易受攻击函数的 CWE-ID,同样和RQ1提到三个基线进行比较。除此之外,作者还引入 VulExplainer,它利用带有蒸馏框架的语言模型来缓解 CWE-ID 分类任务中的数据不平衡。
实验结果同RQ1基本相似,ChatGPT 的预训练阶段并没有充分获得这些知识,因此仍然需要一个微调阶段来提高其性能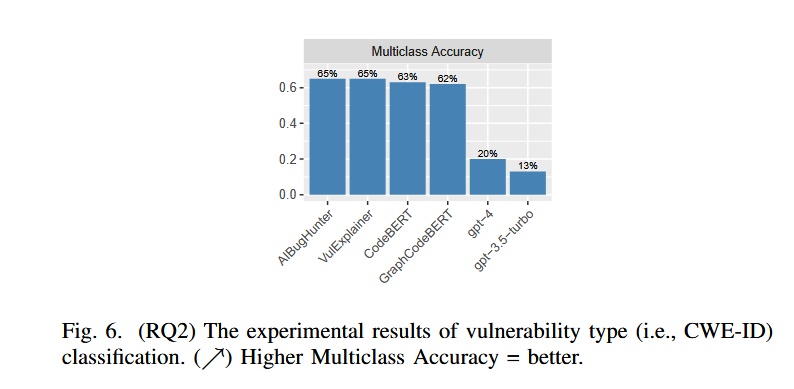
(RQ3) How accurate is ChatGPT for vulnerability severity estimation?
该实验专注于预测易受攻击功能的 CVSS 分数,基线不变,使用均方误差 (MSE) 和平均绝对误差 (MAE)来评估性能
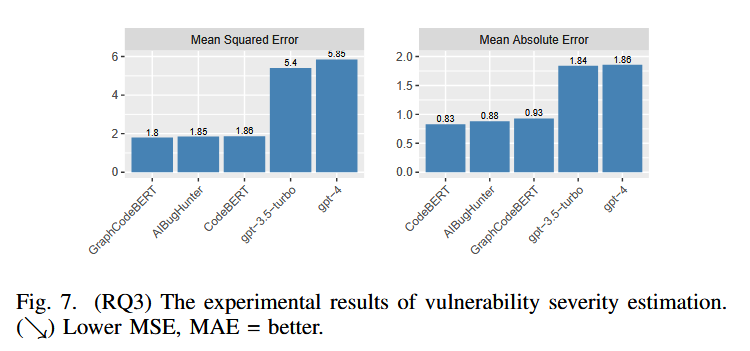
(RQ4) How accurate is ChatGPT for automated vulnerability repair?
该实验专注于为易受攻击的功能生成漏洞修复补丁,AIBugHunter 利用 VulRepair [11] 模型生成修复补丁,从而在漏洞修复问题中取得了最先进的结果,其他方法与上述类似。
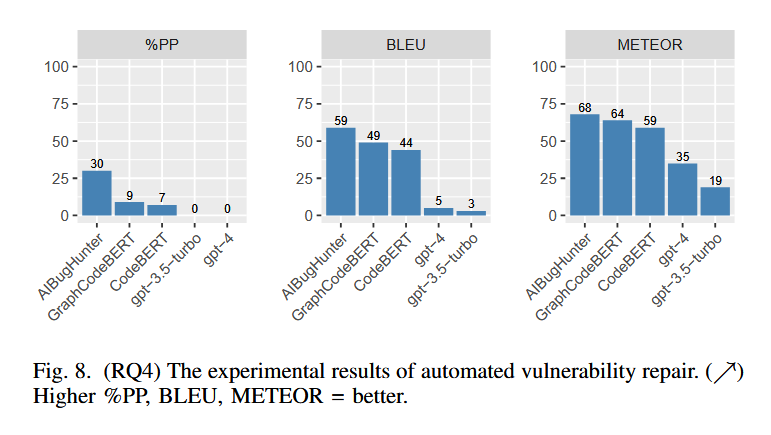
这些结果表明,ChatGPT在这些任务上表现不佳,尤其在漏洞修复任务中完全失败。
Part 8. Discussion & Future Work
研究结果表明,ChatGPT在处理软件漏洞任务时存在显著的局限性,主要原因在于其缺乏针对这些任务的微调。未来的工作方向包括探索如何通过微调增强ChatGPT在软件安全领域的表现,以及进一步优化提示工程以提高其在各类漏洞任务中的表现。此外,未来的研究应关注如何利用ChatGPT的大规模模型能力来增强其对复杂漏洞模式的识别和修复能力。



