[Large Language Model for Vulnerability Detection and Repair: Literature Review and the Road Ahead]
Paper summary
TLDR:
- The paper provides a systematic literature review of the application of Large Language Models (LLMs) in vulnerability detection and repair within the field of Software Engineering (SE).
- The authors aim to summarize the types of LLMs used, categorize the techniques for adapting LLMs to these tasks, and discuss the challenges and future research directions.
- They reviewed 36 primary studies from 2018 to 2024, identifying 15 distinct LLMs and various adaptation techniques.
Algorithmic structure:
- The paper does not present a new algorithm but reviews existing approaches that utilize LLMs for vulnerability detection and repair.
- It discusses three categories of LLMs: encoder-only, encoder-decoder, and decoder-only models, and how they are adapted through techniques like fine-tuning, prompting, and domain-specific pre-training.
Issues or targets addressed by the paper
- The paper addresses the gap in the literature regarding the comprehensive utilization of LLMs for vulnerability detection and repair.
- It highlights the need for a focused review to understand the current state, challenges, and future opportunities in this area.
Detailed Information
Problem Setting
- The problem setting involves source code vulnerability detection and repair, formulated as binary classification and sequence-to-sequence problems, respectively.
- The evaluation setting includes the use of labeled datasets for fine-tuning and the application of LLMs to predict vulnerabilities or generate fixes.
Methodology
- The methodology involves a systematic literature review (SLR) to collect and analyze studies on the use of LLMs for vulnerability detection and repair.
- The review includes a search strategy, study selection process, data extraction, and analysis of the collected papers.
Assumptions
- The authors assume that the selected conferences and journals are representative of the leading research in the field.
- They assume that the collected studies provide a comprehensive view of the current state of LLM applications in vulnerability detection and repair.
Prominent Formulas or Structure
- N/A
Results
- The review identifies a growing interest in LLMs for vulnerability detection and repair, with a peak in 2023 and continued growth in 2024.
- It reveals that encoder-only LLMs dominate vulnerability detection, while encoder-decoder LLMs are more prominent in vulnerability repair.
- The paper discusses the effectiveness of various adaptation techniques, with combination with program analysis showing the highest average improvement.
Limitations
- The authors mention the potential threat to validity due to the risk of inadvertently excluding relevant studies during the literature search and selection phase.
- They acknowledge that the review’s scope is limited to vulnerability detection and repair and does not cover other vulnerability-related tasks.
Confusing aspects of the paper
- The paper is a review and does not contain experimental results or a novel method, so there are no confusing aspects related to methodology or results interpretation.
Conclusions
The author’s conclusions
- The authors conclude that LLMs show promise for vulnerability detection and repair but face challenges such as data quality, complexity of vulnerability data, and the need for high accuracy and robustness.
- They suggest that future research should focus on curating high-quality datasets, exploring repo-level detection and repair, and developing customized LLMs for vulnerability tasks.
Possible future work / improvements
- Future work could involve expanding the review to include other vulnerability-related tasks and a broader range of conferences and journals.
- Improvements could be made in the methodology by incorporating more rigorous quality assessment criteria for the included studies.
- Additionally, the development of new adaptation techniques and the exploration of larger LLMs for vulnerability detection and repair could be promising areas for future research.
Part 1. 标题&作者
标题: Large Language Model for Vulnerability Detection and Repair: Literature Review and the Road Ahead
作者: Zhou, Xin; Kim, Kisub; Xu, Bowen; Liu, Jiakun; Han, DongGyun; Lo, David
Part 2. 摘要
本研究提供了对36项主要研究的系统文献综述,探讨了大语言模型(LLMs)在源代码漏洞检测和修复中的应用,回答3个关键研究问题,我们旨在:( 1 )总结相关文献中使用的LLM;( 2 )分类脆弱性检测中的各种LLM适配技术;( 3 )分类脆弱性修复中的各种LLM适配技术。
Part 3. 导言
传统的技术,如基于规则的检测器或基于程序分析的修复工具,由于高误报率[ 66 ]和它们无法工作于不同类型的漏洞[ 94 ],分别遇到了挑战。
大模型预训练模型在漏洞检测和分析中取得了一定成绩(An empirical study of deep learning models for vulnerability detection,Out of Sight, Out of Mind: Better Automatic Vulnerability Repair by Broadening Input Ranges and Sources.).并指出这是由于它们可以从已知漏洞中自动学习特征,并发现/修复未发现的漏洞,并且利用大规模预训练获得的丰富知识,加强漏洞检测和修复。
在这篇文章中,作者总结了18-24年的36篇论文,提出了多个潜在的研究方向,论文的贡献包括:
- 对最近36篇关于利用LLMs进行漏洞检测和修复的主要研究进行了系统综述。
- 对相关文献中使用的LLMs进行了全面的总结,并分类了用于适应LLMs来完成这两个任务(漏洞检测与修复)的各种技术
- 讨论了使用LLMs进行漏洞检测和修复所面临的关键挑战,并提出了多个潜在的研究方向
Part 4. 结论
研究表明,LLMs在漏洞检测和修复方面具有显著的应用潜力。本文总结了相关的LLM技术,并强调了需克服的挑战,包括模型适应性、数据质量和可解释性问题。此外,研究者应关注未来的研究方向,如漏洞定位和评估。
Part 5. 相关工作
研究问题
RQ1:利用什么LLMs来解决漏洞检测和修复任务
用于漏洞检测的大模型有13种。codebert占据主导地位,其次是gpt3.5。encoder-only的llms占据61.5%(24/39) ,decoder-only的LLMs占28.2 % ( 11 / 39 ),encoder-decoder的LLMs占10.3 %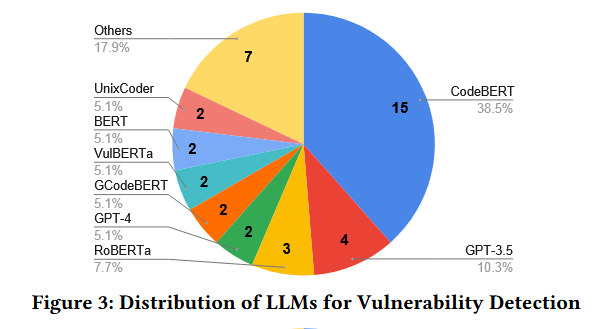
CodeT5 是迄今为止在漏洞修复中占主导地位的LLM,占纳入研究中LLM使用的24.0 % ( 6 / 25 )。领域特异性预训练的Seq2Seq Transformers成为研究频率第二高的模型,占LLMs使用的16.0 % ( 4 / 25 )。就LLMs的类型而言,编码器-解码器LLMs占所使用LLMs的48 % ( 12 / 25 )。之后,仅使用解码器的LLMs和仅使用编码器的LLMs分别占LLMs使用的44 % ( 11 / 25 )和8 % ( 2 / 25 )。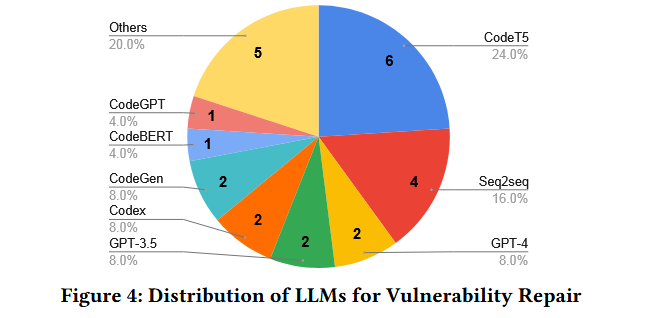
总结:漏洞检测主要用的是encoder-only LLMs,漏洞修复主要用的是encoder-decoder架构的LLMs
RQ2:LLMs如何适用于漏洞检测
具体的技术包括三类:
fine-tuning:该方法使用带标签的数据集来更新LLMs的参数
微调过程通常涉及数据准备、模型设计、模型训练、模型评估等几个步骤/阶段。
根据它们主要针对的阶段将自适应技术分为五组:以数据为中心的创新(数据准备)、与程序分析相结合(数据准备)、LLM +其他深度学习模块(模型设计)、特定领域的预训练(模型训练)和因果学习(训练优化)。
数据为中心的创新:
侧重于优化用于微调LLM的漏洞检测数据。为了解决标签分布不平衡且有噪声和错误以及数据稀缺的问题,研究者提出
- 数据采样:为了解决标签不平衡问题,即在数据集中拥有比脆弱代码更多的非脆弱代码样本。Yang等人[ 86 ]应用了各种数据采样技术。他们发现对原始代码数据进行随机过采样增强了基于LLM的漏洞检测方法学习真实漏洞模式的能力
- 正例和未标记学习:为了解决标签质量问题,例如噪声或错误的标签,Wen等人[ 80 ]提出了PILOT,它仅从正例(脆弱的)和未标记数据中学习,用于漏洞检测。具体来说,PILOT为选定的未标记数据生成伪标签,并通过使用混合监督损失来减轻数据噪声
- 反事实训练:为了增强标注数据的多样性,Kuang等人[ 34 ]提出了在保持语法和语义结构的同时,对源代码中的用户定义标识符进行扰动。这种方法产生了多样化的反事实训练数据,即假设数据(例如,扰动标识符后的数据)不同于实际数据(即,没有扰动的数据),有利于分析某些因素的影响。结合这些反事实数据,丰富了LLMs的训练数据
LLMs与程序分析相结合:
由于预训练使用的是masked language modeling和next token prediction,模型更多捕获的是序列特征而忽略对于代码结构的理解。为此,提出Llm与程序分析相结合的方法。
该思想包括利用程序分析来提取代码中的结构特征/关系,然后将其集成到LLMs中以增强其理解
方法包括:
- 构建AST和PDG,利用这些数据来预训练它们的LLM来预测函数内部的语句级控制依赖和令牌级数据依赖
- 利用程序切片提取控制和数据依赖信息,辅助LLMs进行漏洞检测
- 通过LLM学习静态源代码信息和动态程序执行轨迹来学习程序表示
- 将基于语法的控制流图 ( Control Flow Graphs ,CFGs )分解为多条执行路径,并将这些路径馈送给LLMs进行漏洞检测。
LLMs与其他深度学习模块的结合
LLMs本身也有弊端,大多数LLMs都是基于Transformer架构的,它主要对顺序关系和特征进行建模;一些LLMs (例如, CodeBERT)对输入代码片段的长度进行了限制。例如,漏洞检测中最常用的LLM,CodeBERT,只能处理512个令牌
为了解决以上问题,可以尝试将大模型与其他深度学习模块结合,文章中主要提到两种结合方法:
- LLM + GNN:为了更有效地利用代码的结构特征,Tang等人[ 70 ]提出了CSGVD,它使用图神经网络( GNN )来提取代码的图特征,并将其与CodeBERT提取的特征相结合
- LLM + Bi-LSTM:为了解决LLMs的长度限制,Ziems等人[ 99 ]首先将输入代码分割成多个固定大小的片段。然后,利用BERT对每个片段进行编码,并结合双向长短期记忆网络( BiLSTM )模块来处理BERT在每个片段上的输出。最后,将softmax分类器应用于Bi - LSTM的最后一个隐藏状态,以产生最终的分类分数
领域特定的预训练
在特定领域用特定数据进行预训练,针对该领域特定任务进行微调,能使得模型更好地理解与领域相关的数据,包括三个预训练方法
masked language modeling
- 增强对于代码的理解
contrastive learning
- 最小化相似函数之间的距离,同时最大化不相似函数之间的距离。捕获代码特征
predicting program dependencies
- 学习代码中的依赖关系
在预训练之后,这些特定领域的预训练LLMs在漏洞检测数据集上进行微调,以执行漏洞检测
因果学习
LLMs在面对扰动或者遇到OOD 数据时缺乏稳定性(out-of-distribution)
为了解决这个问题,Rahman等人提出了CausalVul,它首先设计扰动来识别虚假特征,然后在LLMs的基础上应用因果学习算法,特别是do -calculus来促进因果逻辑预测,从而增强LLMs在漏洞检测中的鲁棒性。
zero-shot prompting:它冻结了模型参数,并且不考虑任何有标签的数据
提示工程
设计有效的提示来引导LLMs来进行漏洞检测
few-shot prompting:这也冻结了参数,但考虑了少量有标签的示例数据点。
检索增强
它是指当给定一个测试数据样本时,从训练集中检索出相似的有标签数据样本,并将这些检索到的数据作为例子来指导LLMs在测试样本上的预测。
检索工具:
- BM - 25和TF - IDF
- codebert,该方法首先将代码片段转化为语义向量,然后通过计算两个代码片段各自语义向量的Cosine相似度来量化代码片段之间的相似度。最后根据相似度得分返回相似度最高的代码。
方法如fig5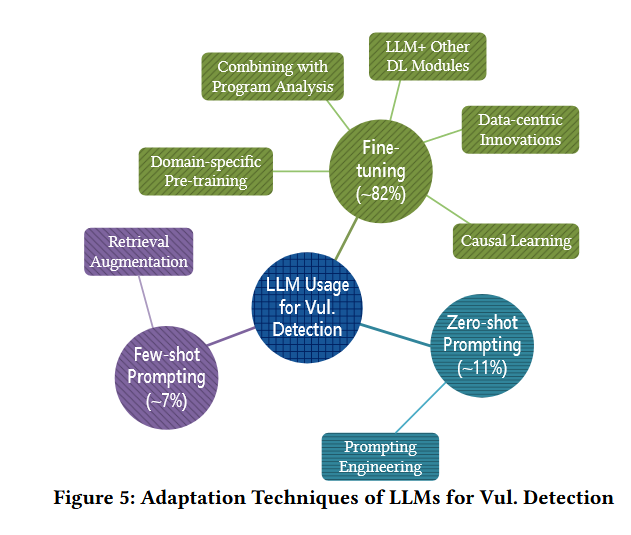
效果如下图
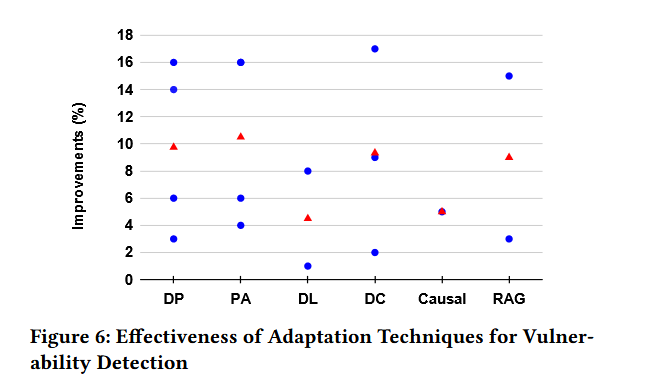
结论:通过与**程序分析(combination with program analysis PA )**技术的结合,实现了最高的平均改进
RQ3:LLMs如何适用于漏洞修复
微调
多样化的相关输入
- 除了输入易受攻击的代码外,结合其他相关输入可以提高LLMs的有效性。比如漏洞代码的AST,漏洞描述,CWE上分享的代码示例等都可以增强大模型对于漏洞代码的修复能力
- 漏洞相关的commit也同样可以提高模型的效率
- 为了解决token超出限制的问题,提出了Fusion-in-decoder框架,将一个长代码函数分割成多个片段,并将这些片段逐个送入LLM中
以模型为中心的创新
- 优先修改LLMs 的架构
领域特定的预训练
- 指在特定领域的数据上预训练LLM,然后针对目标任务对其进行微调
- 提到了迁移学习:首先在bug修复语料上预训练LLM来修复bug,然后在漏洞修复数据集上微调LLM来修复漏洞
强化学习
- 引入强化学习框架Secure Code,结合了句法和语义调优的LLM,为易受攻击的代码生成修复
- 具体来说,他们使用CodeBLEU分数作为句法奖励,BERTScore作为语义奖励。在综合这些奖励之后,他们应用了近似策略优化( PPO )算法来微调CodeGen2 - 7B 模型。
“零”和”少”样本提示
- 提示工程
效果如下图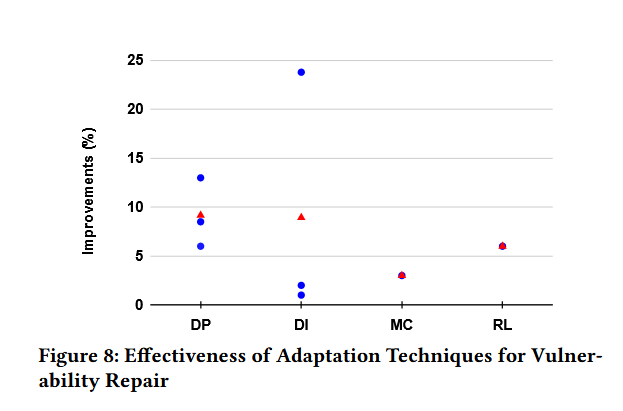
结论:不同的自适应技术导致了不同程度的改善,其中特定领域的预训练( DP )获得了最高的平均改善
Part 8. 讨论&总结
挑战
缺乏高质量的脆弱性数据集
包括噪音或者错误的标签
- 这种数据质量问题主要归因于漏洞自动收集的使用
迄今为止,构建高质量的漏洞基准仍然是一个开放的挑战
更值得注意是:LLMs可能将来自于评估数据集包含在预训练数据集中,这种现象被称为数据污染
高质量的漏洞基准更倾向于与LLMs的预训练语料没有重叠
脆弱性数据的复杂性
- 过程间漏洞在漏洞数据中普遍存在且更有挑战
- 漏洞包含大量的CWE类型,但是LLMs较少与CWE接触
- 在检测跨越多个代码单元的漏洞时,如跨越多个函数,观察到显著的准确性下降。
- 未来的研究应该在设计基于LLM的解决方案时考虑漏洞的复杂性质
输入程序范围窄
- 目前,基于LLM的漏洞检测与修复方案主要针对功能层面的。当面对更宽泛的程序,比如类或者整个仓库时,该方法性能不佳
- 功能级漏洞检测方法可能会忽略跨多个功能或类的漏洞,同时面对跨库多函数修改时也存在不足
- 除了功能外,未来的研究可以提出基于LLM的检测/修复方法,以处理更广泛的程序
高准确度和鲁棒性
- 当前最先进方法的准确性都不高
- LLMs对数据扰动是不稳健的
- 未来的研究应寻求方法来提高基于LLM的解决方案的准确性和鲁棒性。
与开发者建立信任和协同关系。
- 开发人员和基于大模型的漏洞检测和修复方案交互有限,这可能会阻碍实际应用过程中信任和协同的建立
- 未来的研究应该探索更有效的策略来促进开发人员和基于LLM的解决方案之间的协作和信任,通过培育信任和协同,基于LLM的解决方案有可能演变为智能盟友,为开发人员提供更有力的支持
机遇
对高质量的测试集进行评分
- 虽然为大型数据集获得完全正确的标签是昂贵的,但可行的解决方案是固化一个高质量的测试集(远小于整个数据集),以准确评估漏洞检测的进展。
- 未来工作的一个简单方法是将分散在几个单独的研究工作(例如, [ 17,28,36 ])中的人工检查的漏洞数据样本组合起来,形成高质量的测试集。
- 未来的工作可以通过高质量的测试集进行实证研究,以识别漏洞检测的真实进展。此外,通过向社区中添加新的经过人工验证的数据,社区可以维持一个活的高质量测试集。该测试集可以作为漏洞检测的可靠基准
仓库级别的漏洞检测和修复
- 现有的漏洞检测修复技术都是基于函数和行级别的。一个关键的原因是现有研究中主要使用的CodeBERT和CodeT5等小型LLMs的输入长度限制( 512个子令牌)。
- 最近具有更高输入长度容量的大型LLM的出现,如Code Llama ( 16 , 384个子令牌)和GPT - 4 ( 24 576个子令牌),使其能够更有效地处理回购级数据。这为未来的研究提供了一个机会,通过利用这些较大的LLM来探索Repolevel漏洞检测/修复。
使用更大的decoder-only LLms
- 之前对decoder-only架构的模型,特别是参数大于70亿的模型缺少研究,且与ai发展趋势相反
- 23年以来,decoder-only架构模型在代码生成和文本方面表现出色,这使得它们非常适合漏洞修复这一生成任务。
先进的LLM的使用和适应
- LLM Agent:LLM可以作为Agent将复杂的任务分解成更小的组件,并使用多个LLM来处理它们[ 77 ];
- 外部工具的使用:LLMs可以利用外部工具,如搜索引擎、外部数据库和其他资源来增强它们
- 还有许多技术未被开发,比如迭代检索增强、递归检索增强和自适应检索增强等等
针对脆弱性定制Llms
- 利用开源漏洞代码未被充分利用,一个有前途的途径是开发针对脆弱性数据定制的LLM



