Large Language Model for Vulnerability Detection: Emerging Results and Future Directions
Part 1. Title & Source
Title: Large Language Model for Vulnerability Detection: Emerging Results and Future Directions
Conference: ICSE-NIER 2024, Lisbon, Portugal
Part 2. Abstract
本文探讨了大规模语言模型(LLMs),特别是GPT-3.5和GPT-4在软件漏洞检测中的应用。虽然LLMs在自然语言处理任务中表现出色,但其在安全相关任务中的效果尚不明确。研究重点是通过不同的提示语(prompts)来评估LLMs在检测代码漏洞中的性能。实验结果表明,GPT-4比现有最优模型CodeBERT提高了34.8%的准确率,而GPT-3.5在某些场景中也具有竞争力。本文提出了多种改进提示语,并探讨了未来的研究方向。
Part 3. Introduction
软件漏洞是现代软件系统中普遍存在的风险,可能导致敏感信息泄露或系统故障。现有的漏洞检测方法主要依赖于中等规模的预训练模型(如CodeBERT)或从零开始训练的小型神经网络。本研究的目的是探索LLMs在漏洞检测中的潜力,尤其是使用GPT-3.5和GPT-4模型。文中提出,通过适当的提示语设计,可以提升LLMs的分类性能,使其超越传统的预训练模型。
Part 4. Conclusion
研究结果表明,LLMs在漏洞检测中的表现显著优于传统方法。GPT-4与现有方法相比,在准确率方面提升了34.8%。未来的研究可以进一步探索本地化和专用LLMs的开发,以及提升模型在长尾分布数据中的表现。此外,建立开发者与AI系统之间的信任与协作是该领域的关键方向。
Part 5. Related Work
目前在学术领域,尚无大量研究探讨GPT-3.5和GPT-4在漏洞检测中的应用。但已有类似的灰色文献,如BurpGPT与Burp Suite的集成工具和vuln_GPT等。这些研究主要聚焦于漏洞检测的生成式任务,而本研究则专注于改进分类任务的提示语设计。
Part 6. Method & Algorithm
本文采用了提示语设计(prompt design)的创新方法来增强LLMs的表现:
基础提示(P): 简单描述任务,要求模型判断代码是否存在漏洞。
$f_{\boldsymbol{promp}\boldsymbol{t}}(x)=$ Code is $[X].It$ is $[Z]$ $V=\left{\begin{array}{l}+,if:Z=vulnerable,\-,if:Z=non-vulnerable,\end{array}\right.$ 下图是promots的设计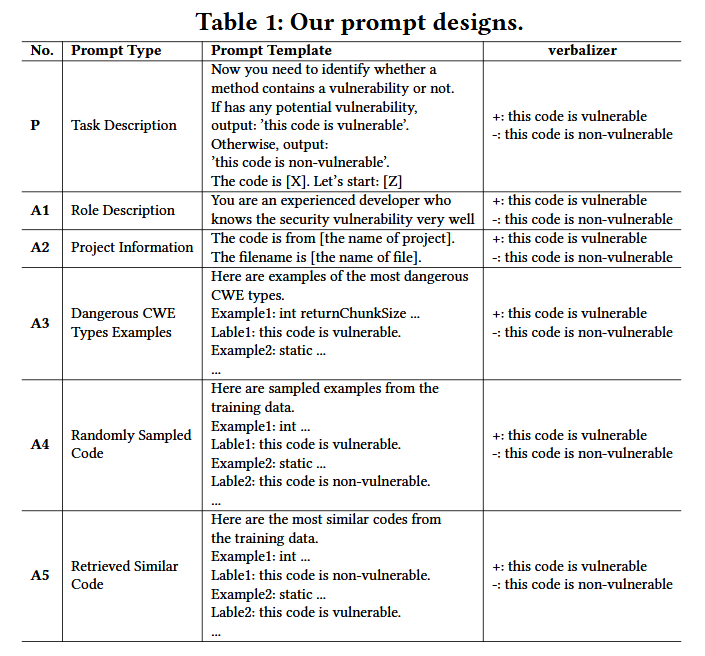
作者设计的是空的系统消息和一个用户消息。P是base promot,并使用$A^*$ 对P进行了增强
扩展提示:
- 角色描述(A1): 模拟开发者角色,提高模型的上下文理解能力。
- 项目信息(A2): 加入代码的项目和文件名信息,以提高提示语的针对性。
- CWE示例(A3): 引入常见漏洞类型的示例,为模型提供更丰富的参考信息。
- 随机样本(A4): 从训练集中随机选取示例,辅助模型学习。
- 相似代码检索(A5): 通过计算语义向量的余弦相似度,从训练集中检索最相似的代码示例。
模型的评估主要基于GPT-3.5和GPT-4,并与CodeBERT进行了比较。
Part 7. Experiment
实验数据集来自Pan等人(2023)的漏洞修复提交数据集。本研究主要采用C/C++语言的开源项目作为测试集,并从训练集中选取相应的修复提交进行模型评估。采用的评估指标包括准确率、精确率、召回率、F1得分和F0.5得分。实验结果显示: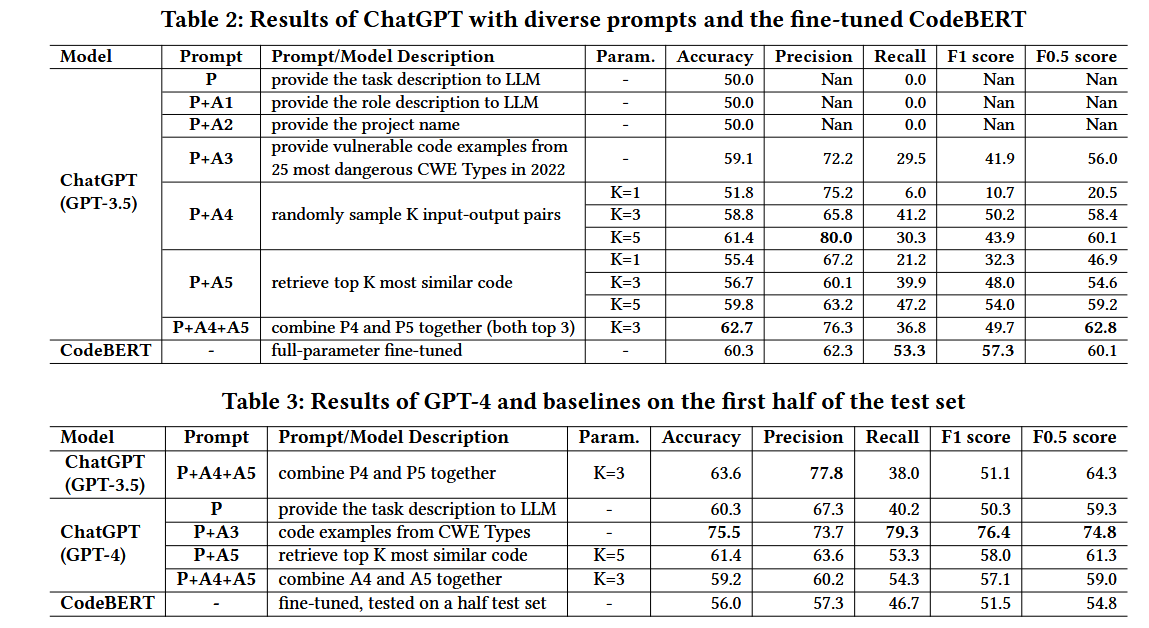
- GPT-3.5:通过不同提示语组合,性能逐步提升。组合P+A4+A5时,准确率达到了62.7%,比CodeBERT高出4%。CodeBERT和GPT - 3.5的不同优势。GPT - 3.5显示出更高的准确率,表明其在减少误报方面的能力。另一方面,CodeBERT表现出更高的Recall值,这表明CodeBERT能够识别更多的漏洞
- GPT-4:在部分测试集上的评估中,GPT-4使用CWE提示语(P+A3)时,准确率提升至75.5%。这表明GPT-4在漏洞检测任务中的潜力远高于Codebert。
威胁:
- ChatGPT可能存在数据泄露,评估中使用的数据集可能与用于训练ChatGPT的数据重叠。由于ChatGPT是一个闭源模型,可能缺乏验证这种重叠是否存在的手段。
- 漏洞函数和非漏洞函数的比例相等,等数据比并不能真实地表示实际的漏洞预测问题,因为漏洞代码是软件系统中的少数。且可能会导致本实验metrics虚高
Part 8. Discussion & Future Work
本文提出了以下未来研究方向:
- 本地化与专用LLMs的开发: 针对敏感代码无法外传的问题,开发本地化模型(如LLaMA),以满足隐私保护需求。
- 提高模型的精度与鲁棒性: 通过集成学习和对抗性变换(如变量重命名)来提升模型性能。
- 应对长尾分布数据的挑战: 针对漏洞类型的长尾分布问题,探讨生成数据增强的方法以提高模型在稀有类型上的表现。
长尾分布是指某些类别的数据非常丰富,而其他类别的数据极其稀少,这在漏洞检测领域常表现为某些CWE类型(Common Weakness Enumeration)样本多,而大部分其他类型样本极少。这种不平衡导致模型在常见类型上性能良好,但在稀有类型上表现不佳。
应对方法包括:
数据增强(Data Augmentation)
- 方法: 使用语言模型(如GPT-4)生成一些合理的缓冲区溢出代码片段。
- 效果: 增加模型在稀有类型上的训练样本,从而改善分类性能
少样本学习(Few-shot Learning)
- 方法: 在提示语中加入几条稀有漏洞类型的代码示例,增强模型的识别能力。
- 效果: 提升模型对低频类别的识别准确率。
集成学习(Ensemble Learning)
- 方法: 将多个模型的预测结果进行组合,选取高置信度的预测作为最终结果。比如GPT-4负责处理生成的代码段并给出初步判断,CodeBERT用于编码语义特征,特别是在结构性代码分析上具有优势,集成多个模型的结果,通过投票或加权平均得到最终预测。
- 效果: 通过不同模型的互补性,提高在长尾类别上的检测效果。
迁移学习(Transfer Learning)
- 方法: 先在通用的代码数据集上进行预训练,再微调模型用于具体的漏洞检测任务。
- 效果: 利用迁移学习,模型在数据稀缺的情况下也能捕捉到有用的特征。
4.建立开发者与AI系统的信任与协作: 探索如何更好地与开发者协作,使AI系统成为开发者的智能助手。



