Adversarial Examples for Models of Code
OOPSLA
Part1. Title&Source
Title: Adversarial Examples for Models of Code
Authors: Noam Yefet, Uri Alon, Eran Yahav
Source: Technion, Israel
Paper link
Part2. Abstract
本文展示了基于神经网络的代码模型在代码分析任务中的脆弱性,尤其是在方法名预测和漏洞检测中。这些模型容易受到对抗样本的攻击。作者提出了一种新的白盒攻击方法,称为离散对抗程序操作(Discrete Adversarial Manipulation of Programs,DAMP),通过在不改变代码语义的前提下引入小的扰动来进行攻击。实验表明,这种攻击在不同的神经架构(code2vec、GGNN和GNN-FiLM)中非常有效,且成功率最高可达89%。文中还讨论了几种防御措施,一些防御可以显着降低攻击者的成功率。
Part3. Introduction
近年来,神经模型在代码分析任务中取得了显著进展,如变量名和类型预测、代码生成、漏洞检测等。然而,类似于计算机视觉领域,神经网络模型也面临对抗样本的威胁。在图像分类中,加入细微的扰动可以改变模型的输出,而代码领域中的对抗攻击更加复杂,因为代码是离散的,且扰动不能影响其语义。本文旨在通过对抗样本的生成来攻击代码模型,使其输出错误预测。为此,作者提出了DAMP方法,通过变量重命名和插入无用代码的方式生成对抗样本。
Part4. Conclusion
本文展示了DAMP在代码模型中的有效性,并通过实验验证了其对code2vec、GGNN和GNN-FiLM架构的攻击能力,成功率最高可达94%。此外,文中提出了几种防御机制,并对它们的有效性进行了讨论。实验结果表明,通过适当的防御措施,可以显著降低攻击成功率,同时仅对模型的准确性产生轻微影响。未来的工作将进一步探索更多的对抗样本生成策略,并优化防御机制以提高模型的鲁棒性。
Part5. Related Work
本文参考了图像分类中的对抗样本生成技术,如FGSM(Fast Gradient Sign Method)以及NLP中的对抗攻击方法。虽然图像和文本领域的对抗样本生成已经有了较多研究,但将这些方法直接应用到代码领域存在挑战。代码不仅是离散的,还具有特定的语法和语义约束。此外,代码的结构和语义使得简单的字符替换或词汇级扰动难以实现有效的攻击。
Motivation
绕过语义标记,攻击方法包括:
- rename variable
- insert unused code
绕过 Bug 检测
- 在C#的代码片段中,GGNN模型正确地选择了
DestinationType作为方法Equals中正确的变量。然而,通过DAMP方法,攻击者重命名了另一个方法中的局部变量destination为无关的名字scsqbhj,模型错误地选择了SourceType作为预测结果。
- 在C#的代码片段中,GGNN模型正确地选择了
Part6. Model
DAMP攻击方法适用于任何可对输入计算梯度的神经网络模型,主要针对变量重命名和无用代码插入两种语义保持的代码扰动。DAMP方法基于梯度反向传播,通过计算模型输入的梯度来选择最优的扰动方向,并逐步修改代码的输入,从而生成对抗样本。本文重点评估了三种架构:code2vec、GGNN和GNN-FiLM。这些模型分别用于代码方法名预测和变量错误使用检测任务。
技术细节包括:
- DAMP技术通过梯度下降来探索程序空间,使得模型的预测从正确标签转变为攻击者指定的错误标签。
- 在目标攻击中,DAMP计算相对于目标标签的梯度,并根据梯度方向修改输入代码。通过反复迭代,逐步调整代码直到模型输出攻击者期望的错误标签。
- 在非目标攻击中,DAMP则通过梯度上升的方式增加损失函数,推动模型向任意错误预测方向发展。
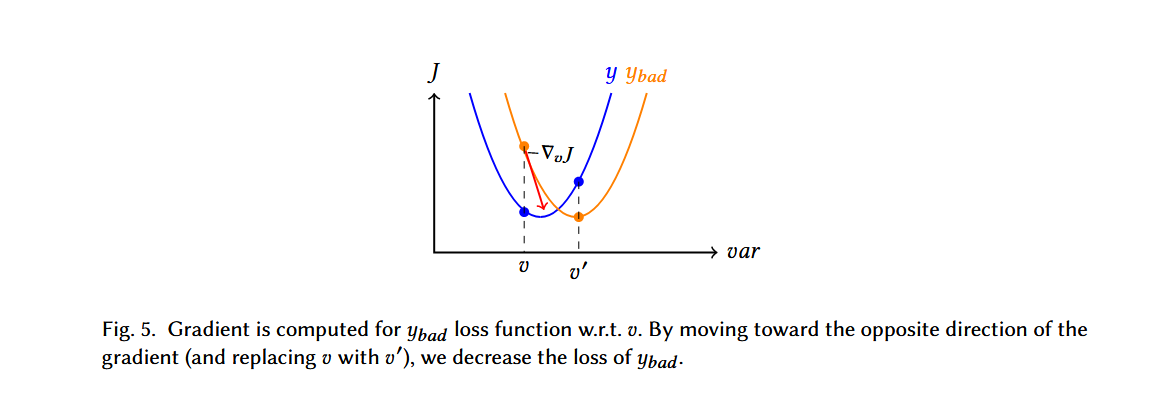
由于代码是离散对象,对代码进行修改时必须确保其语义保持不变,且代码的空间非常大,因此穷举搜索等简单方法不可行。
语义保持的代码变换
为了生成语义保持的对抗样本,作者提出了两种主要的代码变换方法:
- 变量重命名(Variable Renaming):通过重命名局部变量,使模型预测出错误的标签。例如,将变量
array重命名为ttypes,保持代码功能不变的情况下使得模型输出错误结果。 - 插入无用代码(Dead Code Insertion):通过在代码中插入无用的变量声明或其他冗余代码,保持代码功能不变,同时扰乱模型的预测。例如,插入一个未使用的变量声明,可以改变模型的预测结果。
DAMP方法
是一种通过梯度计算来生成对抗样本的方法,核心思想包括:
不改变模型参数:在对抗攻击过程中,DAMP方法不修改模型的权重,而是通过修改输入(代码)来改变模型的预测。
使用梯度引导代码修改:DAMP方法通过计算模型输入的梯度来选择变量或代码的最优修改点。具体来说,作者使用目标标签 $y_{bad}$ 计算损失函数$J(\theta,x,y_{bad})$,并通过梯度反向传播来逐步修改代码中的变量名或插入无用代码,直到模型输出错误结果。公式描述:$v’=v-\eta\cdot\nabla_vJ(\theta,P,y_{bad})$
a. 变量名的扰动:
由于变量名是离散的符号,DAMP方法通过将变量名表示为一个one-hot向量来处理。经过梯度计算后,DAMP通过argmax操作选择最合适的变量名替换。这一过程确保变量名的修改既能保持代码语义不变,又能导致模型的错误预测。
b. 无用代码的插入:
DAMP方法还可以通过在代码中插入无用变量来实现对抗攻击。无用变量的插入不影响代码的实际功能,但通过梯度计算和变量名选择,DAMP可以使模型输出错误的预测结果。
搜索与收敛
DAMP方法在生成对抗样本时,通过广度优先搜索(BFS)策略进行代码修改的多次尝试。搜索的宽度和深度由两个超参数(top-k和depth)控制,分别决定了在梯度下降中的每一步候选变量名的数量和最大迭代次数。虽然梯度下降并不能保证在非凸损失函数下的全局最优收敛,但在大多数情况下,DAMP能够成功找到使模型预测错误的对抗样本。
- 广度优先搜索(BFS):DAMP采用BFS策略来探索变量名或代码片段的修改。每次修改都根据梯度计算选择最优的变量名替换,直至找到能够使模型输出错误预测的代码。
- 收敛性:虽然DAMP无法保证每次都能成功生成对抗样本,但实验表明,在大多数情况下,该方法能够找到有效的对抗样本。对于那些没有找到对抗样本的情况,DAMP会停止搜索并认为攻击失败。
防御方法:
without re-training
- No Vars(变量名消除)
- 原理:在测试时,将所有的变量名替换为“UNK”(即unknown),从而阻止模型利用变量名进行预测。
- 优势:这种方法通过完全消除变量名的影响,因此对变量名重命名攻击具有100%的防御能力,保证了极高的鲁棒性。
- 劣势:由于该方法抹去了变量名信息,模型在没有攻击时的性能会受到严重影响,特别是在变量名对于任务结果至关重要的场景下。
- Outlier Detection(离群点检测)
原理:该方法通过检测输入代码中的异常变量名来识别并移除潜在的对抗样本。具体来说,使用变量名的嵌入向量来计算变量之间的距离。如果某个变量名的嵌入向量与其他变量之间的距离过大,则将其识别为离群点,并用“UNK”替换该变量名。$z^*=\arg\max_{z\in Var(c)}\sum_{v\in Sym(c),v\neq z}\frac{|vec(v)-vec(z)|}{|Sym(c)|-1}$> 其中,z∗z^*z∗ 是距离其他符号最远的变量,若其距离大于设定的阈值 σ\sigmaσ,则将该变量替换为“UNK”。
优点:该方法在不严重影响模型准确性的前提下,可以有效检测和移除异常的变量名,从而防御对抗样本。
调优:通过调整离群点检测的阈值 $σ$,可以在模型鲁棒性和性能之间进行平衡。实验中表明,合理设置阈值可以在仅轻微降低模型性能的情况下大幅提升模型的防御能力。
with re-training
- Train Without Vars(无变量训练)
- 原理:在训练和测试时都将所有的变量名替换为“UNK”,使模型完全依赖代码的其他结构或信息,而不是变量名。
- 优势:这种方法保证了模型对变量名重命名攻击的100%鲁棒性,因为模型在训练过程中从未依赖变量名进行预测。
- 劣势:由于变量名是代码的重要组成部分,完全抹去变量名可能导致模型性能下降,特别是在需要依赖变量名信息的任务中。
Adversarial Training(对抗训练)
- 原理:在训练过程中,不仅使用原始的训练数据,还在每个训练样本上生成对抗样本,并同时训练模型在原始数据和对抗样本上都能表现良好。对抗样本的生成可以使用非目标攻击(如DAMP的非目标攻击),通过梯度上升生成扰动后的输入
$J_{adv}(\theta,x’,y)=J(\theta,x,y)+J(\theta,x’,y)$
- 优势:对抗训练可以有效增强模型的鲁棒性,确保模型在面对对抗样本时仍能正确预测。
劣势:对抗训练需要额外的训练时间,训练过程大约比普通训练慢三倍。
Adversarial Fine-Tuning(对抗微调)
- 原理:首先用原始训练数据训练模型以达到最佳性能,然后在训练结束后,通过对抗样本进行微调,使模型在保持原始性能的基础上增强其对对抗样本的鲁棒性。
- 优势:这种方法先确保模型在正常输入上的性能,然后再通过短期的对抗微调增强对对抗样本的抵抗能力。
- 劣势:虽然微调能增强对抗鲁棒性,但在实际攻击场景中,这种方法的效果可能不如全面的对抗训练。
限制词汇量(Vocabulary Limitation)
- 原理:通过限制模型训练时的变量名词汇量,忽略罕见的变量名。例如,将变量名词汇限制为前1万、5万或10万个高频词汇,其余的变量名在训练和测试时都被替换为“UNK”。
- 优势:这种方法通过降低模型对不常见变量名的依赖,减少对罕见变量名的误分类,从而提升鲁棒性。
- 劣势:减少词汇量可能会对模型的整体性能产生影响,特别是当变量名在代码任务中非常重要时。
Part7. Experiment
实验部分通过攻击Java和C#语言中的代码模型验证了DAMP方法的有效性。在针对code2vec的实验中,作者使用了Java-large数据集,并选择了模型准确预测的代码片段进行攻击。针对GGNN和GNN-FiLM,实验使用了C#项目中的VarMisuse任务,评估了变量重命名和无用代码插入两种攻击策略。实验结果显示,DAMP攻击在非目标攻击中成功率高达94%,而在目标攻击中成功率也达到了89%。
Part8. Discussion&Future Work
作者提出了多种防御措施来应对对抗攻击,包括变量匿名化、离群检测、对抗训练等。实验表明,某些防御策略能够显著降低攻击成功率,但也可能导致模型性能的下降。未来工作中,作者计划扩展对更多神经架构的评估,探索其他类型的对抗攻击,并进一步优化防御机制以提高代码模型的鲁棒性



