工具用法总结
pytorch篇
- torch.matmul:用于执行矩阵乘法。它支持多种维度的矩阵运算,包括两个2D矩阵的乘法,以及高维矩阵的乘法(批量矩阵乘法)
该行为取决于张量的维数
- 如果两个张量都是一维,则返回点积(标量)。
1 | # vector x vector |
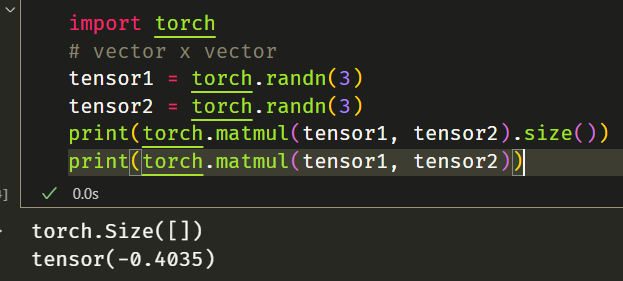
- 如果两个参数都是二维的,则返回矩阵-矩阵乘积。
1 | # batched matrix x batched matrix |
- 如果第一个参数是一维,第二个参数是二维,则为了矩阵乘法的目的,在其维度前添加 1。矩阵相乘后,前面的维度将被删除。
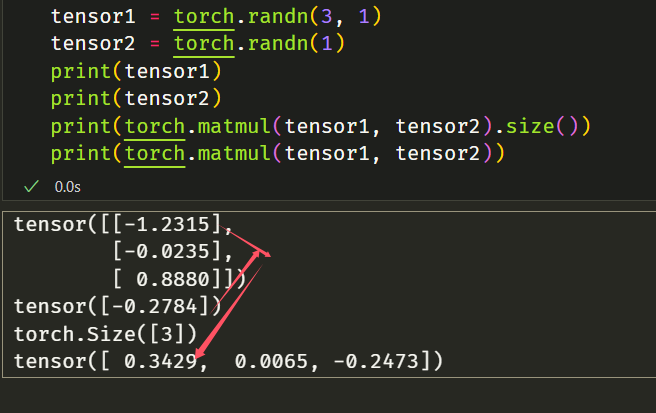
- 如果第一个参数是二维的,第二个参数是一维的,则返回矩阵向量乘积。
1 | # matrix x vector |
每一行分别与向量相乘
- 如果两个参数至少为一维且至少一个参数为 N 维(其中 N > 2),则返回批量矩阵乘法
1 | # batched matrix x broadcasted vector |
- nn.Linear :线性层
Parameters
• in_features (int) – size of each input sample
• out_features (int) – size of each output sample
• bias (bool) – If set to False, the layer will not learn an additive bias. Default: True
- • in_features (int) – size of each input sample
- • out_features (int) – size of each output sample
- • bias (bool) – If set to
False, the layer will not learn an additive bias. Default:True

1 | m = nn.Linear(20, 30) |
PyTorch 允许张量成为现有张量的视图。视图张量与其基本张量共享相同的基础数据。支持视图避免了显式数据复制,从而使我们能够进行快速且内存高效的重塑、切片和逐元素操作
例如,要获取现有张量 t 的视图,可以调用 t.view(…)
1 | t = torch.rand(4, 4) |
- tensor transpose 转置行和列
1 | base = torch.tensor([[0, 1,4],[2, 3,5]]) |
在PyTorch中,torch.randint(low, high, size)函数用于生成一个随机整数张量。这里的low和high分别表示生成随机数的下限和上限(上限是不包含的),而size参数指定了输出张量的形状。
当你使用torch.randint(2, 8, (3,))时,你实际上是在创建一个形状为(3,)的一维张量,其中包含从2到7(包括2,不包括8)的随机整数。这里的(3,)表示这个张量有3个元素
1 | batch_size = 2 |
用于在指定的维度上插入一个大小为1的维度。
例如,如果你有一个一维张量 x = torch.tensor([1, 2, 3, 4]),使用 torch.unsqueeze(x, 0) 会在位置0(最前面)插入一个新的维度,结果张量的形状会变成 (1, 4)。如果你使用 torch.unsqueeze(x, 1),则会在位置1(最后面)插入一个新的维度,结果张量的形状会变成 (4, 1)
在实际应用中,dim 参数的值决定了新维度被插入的位置。例如:
dim=0会在张量的最前面插入一个新维度。dim=-1会在张量的最后面插入一个新维度。- 如果你的输入张量是二维的,比如
(3, 4),使用torch.unsqueeze(input, 0)会得到一个形状为(1, 3, 4)的张量,而torch.unsqueeze(input, -1)会得到一个形状为(3, 4, 1)的张量 - dim=n,即在第n为插入一个维度
Parameters
1 | x = torch.tensor([1, 2, 3, 4]) |
对input和 mat2 中存储的矩阵执行批量矩阵-矩阵乘积。
input 和 mat2 必须是 3-D 张量,每个张量包含相同数量的矩阵。
if input is a (b×n×m) tensor, mat2 is a (b×m×p) tensor, out will be a (b×n×p)tensor.
1 | input = torch.randn(10, 3, 4) |
numpy篇
- np.array:用于创建一个数组。这个数组可以是一维的,也可以是多维的,并且可以包含任何数据类型,如整数、浮点数、字符串等。数组中的所有元素必须是相同的数据类型。
1 | np.array([1, 2, 3, 4, 5]) |
- np.power(x, y): 这里x可以是数组
$$
np.power(x, y) = x^y
$$
- np.sin() sp.cos():
1 | np.sin(np.pi/2.) |
- np.zero(x):补充x位的0
1 | a = np.arange(6).reshape((3, 2)) |
数组的上三角形。
返回一个数组的副本,其中第 k 个对角线下方的元素已为零。对于 ndim 超过 2 的数组,triu 将应用于最后两个轴
1 | import numpy as np |
同理,
numpy.tril:数组的下三角形。
Latex篇
论文轮廓
1 | \documentclass[twocolumn]{article} |
图片插入
1 | \usepackage{graphicx} % 在导言区引入graphicx包 |
文献引用
1 | latex |
• 使用 \cite{引用标记} 在正文中引用参考文献。
1 | \cite{ref1} |
Transformers
pipelines
Transformers 库中最基本的对象是pipeline()函数。它将模型与其必要的预处理和后处理步骤连接起来,使我们能够直接输入任何文本并获得答案。当第一次运行的时候,它会下载预训练模型和分词器(tokenizer)并且缓存下来
1 | from transformers import pipeline |
1 | classifier( |
pipeline()在接收文本后,通常有三步:Tokenizer、Model、Post-Processing
1)Tokenizer
与其他神经网络一样,Transformer 模型不能直接处理原始文本,故使用分词器进行预处理。使用AutoTokenizer类及其from_pretrained()方法
1 | from transformers import AutoTokenizer |
若要指定我们想要返回的张量类型(PyTorch、TensorFlow 或普通 NumPy),我们使用return_tensors参数
1 | raw_inputs = [ |
PyTorch 张量的结果:
输出本身是一个包含两个键的字典,input_ids和attention_mask。
1 | { |
2)Model
Transformers 提供了一个AutoModel类,它也有一个from_pretrained()方法:
1 | from transformers import AutoModel |
如果我们将预处理过的输入提供给我们的模型,我们可以看到:
1 | outputs = model(**inputs) |
Transformers 中有许多不同的架构可用,不同的模型架构被设计用于特定的自然语言处理(NLP)任务。每种架构在基础模型的基础上添加了不同的“头部”(head),以适应特定的任务需求,清单:
*Model(retrieve the hidden states)*ForCausalLM*ForMaskedLM*ForMultipleChoice*ForQuestionAnswering*ForSequenceClassification*ForTokenClassification
and others
Model
不同的模型架构被设计用于特定的自然语言处理(NLP)任务。每种架构在基础模型的基础上添加了不同的“头部”(head),以适应特定的任务需求
用途:
- 特征提取:用作其他任务的特征提取器,获取输入文本的上下文表示。
- 自定义任务:在基础模型上添加自定义的输出头部,以适应特定需求。
- 研究目的:分析模型内部的表示或进行模型蒸馏等研究工作
1 | from transformers import BertModel, BertTokenizer |
ForCausalLM(因果语言建模)
ForCausalLM类(例如GPT2LMHeadModel)专为因果语言建模任务设计。因果语言模型通过仅利用序列中前面的词(左侧上下文)来预测下一个词,实现文本生成。
用途:
- 文本生成:自动补全、续写、生成创意文本。
- 对话系统:构建聊天机器人,生成对话回复。
- 内容创作:辅助写作、代码生成等
1 | from transformers import GPT2LMHeadModel, GPT2Tokenizer |
ForMaskedLM(掩码语言建模)
*ForMaskedLM类(例如BertForMaskedLM)专为掩码语言建模任务设计。这类模型通过预测序列中被掩盖的词来理解上下文,利用双向(前后)上下文信息。
用途:
- 填充缺失词:在句子中填补被掩盖的词语。
- 预训练任务:用于预训练模型,如 BERT。
- 文本理解:增强模型对上下文的理解能力。
1 | from transformers import BertForMaskedLM, BertTokenizer |
ForMultipleChoice
ForMultipleChoice类(例如BertForMultipleChoice)用于多选题任务。该模型能够处理多个选项,并评估每个选项与给定上下文或问题的匹配程度,选择最合适的答案。
用途:
- 多选问答:选择最佳答案,如标准化考试问题。
- 推荐系统:从多个候选项中选择最适合的选项。
- 决策支持:在多种可能的行动方案中进行选择。
1 | from transformers import BertForMultipleChoice, BertTokenizer |
ForQuestionAnswering(问答)
描述:
*ForQuestionAnswering类(例如BertForQuestionAnswering)专为问答任务设计。模型通过给定上下文和问题,预测答案在上下文中的起始和结束位置。
用途:
- 信息检索:从文档中提取精确答案。
- 对话系统:在对话中提供具体答案。
- 知识问答:基于知识库或文本回答问题。
示例:
1 | from transformers import BertForQuestionAnswering, BertTokenizer |
ForSequenceClassification(序列分类)
描述:
*ForSequenceClassification类(例如BertForSequenceClassification)用于对整个输入序列进行分类。模型在基础模型的顶部添加了一个分类头部,以输出类别的概率分布。
用途:
- 情感分析:判断文本的情感倾向(如积极、消极、中性)。
- 主题分类:将文本归类到不同的主题或类别中。
- 垃圾邮件检测:识别并分类垃圾邮件。
- 语言检测:确定文本的语言类别。
示例:
1 | from transformers import BertForSequenceClassification, BertTokenizer |
ForTokenClassification (标记分类)
描述:
ForTokenClassification类(例如BertForTokenClassification)专为标记级分类任务设计。模型在每个输入标记(token)的表示上添加了分类头部,以对每个标记进行分类。
用途:
- 命名实体识别(NER):识别文本中的实体,如人名、地名、组织机构等。
- 词性标注(POS):为每个词分配词性标签,如名词、动词等。
- 文本分块:将文本分成不同的块或片段,进行标签分类。
- 语义角色标注:识别句子中各个成分的语义角色。
1 | from transformers import BertForTokenClassification, BertTokenizer |
3)Post-Processing
模型最后一层输出的原始**非标准化分数**。要转换为概率,它们需要经过一个SoftMax层(所有 Transformers 模型都输出 logits,因为用于训练的损耗函数一般会将最后的激活函数(如SoftMax)与实际损耗函数(如交叉熵)融合 。
1 | import torch |
model
1)创建Transformer
1 | from transformers import BertConfig, BertModel |
2)不同的加载方式
1 | from transformers import BertModel |
3)保存模型
1 | model.save_pretrained("directory_on_my_computer") |
4)使用Transformer model
1 | sequences = ["Hello!", "Cool.", "Nice!"] |
model.generate()总结
第一次做实验,对于各个参数的不熟悉导致我花了导量时间进行代码调试,现在进行总结,帮助我理解。
参数
top_p核采样- 核采样是一种基于概率分布的采样方法,用于从语言模型生成的词汇分布中选择下一个词。它的核心思想是选择概率累积达到阈值
p的最小词汇集合(称为“核”),然后从这个集合中进行采样 - 工作过程
- 排序:首先,将所有候选词按概率从高到低排序。
- 累积概率:计算从最高概率开始,逐步累加词汇的概率。
- 选择核:确定最小的词汇集合,使其累积概率至少为
p。这个集合就是“核”。 - 采样:从这个“核”中按概率分布随机选择下一个词汇。
- 较低的
p(如0.6)会限制模型只从高概率词汇中选择,生成内容更确定但可能缺乏多样性。较高的p(如0.9)则允许更多低概率词汇参与采样,增加生成内容的多样性
- 核采样是一种基于概率分布的采样方法,用于从语言模型生成的词汇分布中选择下一个词。它的核心思想是选择概率累积达到阈值
max_length- 控制生成文本的最大长度。包括输入token的数量在内
min_length- 设置生成文本的最小长度,确保生成的文本不会太短
do_sample- 是否在生成文本时使用采样策略。如果设置为False,则使用贪心策略进行解码(贪心算法可能导致局部最优)
temperature- 用于调整生成过程中的随机性程度。数值越大,生成的文本越随机
repetition_penalty- 用来防止文本重复的参数,使得模型在选择已经出现的词时变得更加谨慎。为了避免生成的文本过于重复,通过调节这个参数,可以降低重复词汇的选择概率,提高文本的多样性和可读性
pad_token_id- 用于填充的token ID。在文本生成中,如果生成的文本短于
max_length,这个ID将被用来填充生成文本
- 用于填充的token ID。在文本生成中,如果生成的文本短于
eos_token_id- 定义结束序列的token ID。当模型生成了这个ID对应的token时,将停止生成进一步的token。
num_beams- 使用束搜索(Beam Search)策略时,束的大小。提高这个值可以提高文本的质量,但也会增加计算量
use_cache- 是否使用模型的past key/values来加速生成。对于某些模型,这可以显著提高生成的速度。
防止EOS过早出现
调整
max_length和min_length使用
eos_token_id和pad_token_id参数- 如果知道EOS标记的token ID,可以尝试在生成时不包含该EOS标记的ID,或者通过使用
pad_token_id替换掉eos_token_id,让模型知道还不应该结束。
- 如果知道EOS标记的token ID,可以尝试在生成时不包含该EOS标记的ID,或者通过使用
调整
length_penaltylength_penalty参数用于调节生成文本的长度偏好。数值大于1会鼓励模型生成更长的序列,可能有助于减少EOS标记过早出现的情况
清晰的任务指示(Prompt Engineering)
对EOS进行惩罚
- 使用logit_bias参数调整EOS的生成概率。
logit_bias参数允许我们为特定的token IDs设置一个偏置值,从而影响它们被生成的概率。通过给EOS token设置一个负的偏置值,可以降低它被早期选择的可能性。
- 使用logit_bias参数调整EOS的生成概率。
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |
常用算法
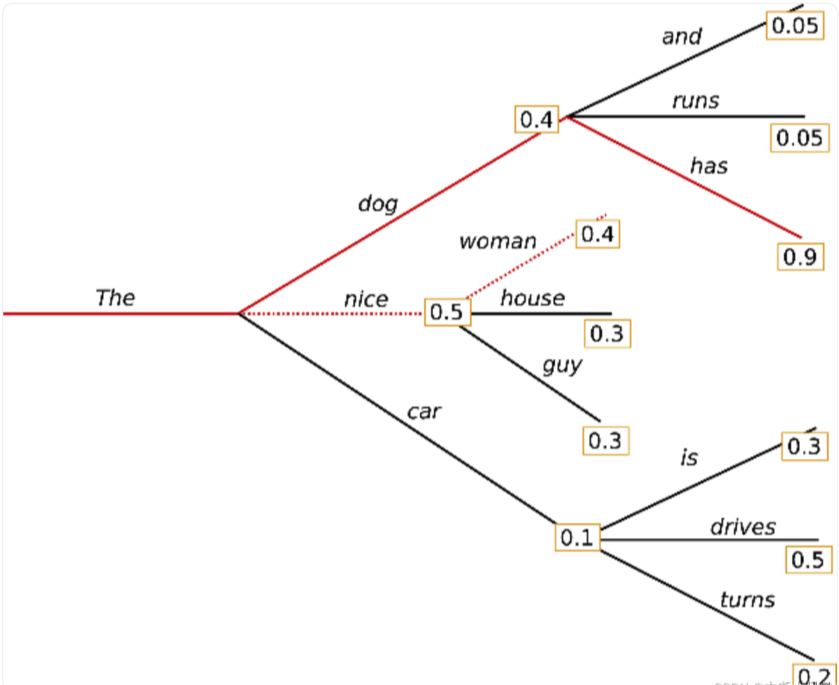
- greedy decoding:当 num_beams=1 而且 do_sample=False 时,调用 greedy_search()方法,每个step生成条件概率最高的词,因此生成单条文本。
贪婪搜索,每个时间步 t tt 都选概率最高的那个词
$$w_t=argmax_wP(w|w_{1:t-1})$$
- multinomial sampling:当 num_beams=1 且 do_sample=True 时,调用 sample() 方法,对词表做一个采样,而不是选条件概率最高的词,增加多样性。
- beam-search decoding:当 num_beams>1 且 do_sample=False 时,调用 beam_search() 方法,做一个 num_beams 的柱搜索,每次都是贪婪选择top N个柱。
beam search每个时间步选择最可能的 Top - num_beams 个词,解决了贪婪搜索擦肩而过的风险。如图例子,num_beams=2,第一步选了概率最高的序列 the nice(0.5) 和 the dog(0.4),第二步选了概率最高的序列 the dog has(0.4✖️0.9=0.36)和 the nice woman(0.5✖️0.4=0.20)。
如果生成长度是提前可预知,比如摘要、翻译,这种用beam search好;但开放式生成,比如对话,故事生成等,输出长度变化比较大,就不太适合用beam search了。
beam search容易重复生成单词。由于通过大量实验才能达到“禁止生成重复n-gram” 和 “允许周期性生成重复n-gram” 的平衡,所以在开放式生成任务上不太好用这种惩罚来控制重复。
人类往往说话时不是总选择高概率的词作为下个词,而是经常猝不及防,出其不意,如图对比。所以beam search还是有很大问题的。
- beam-search multinomial sampling:当 num_beams>1 且 do_sample=True 时,调用 beam_sample() 方法,相当于每次不再是贪婪选择top N个柱,而是加了一些采样。
- diverse beam-search decoding:当 num_beams>1 且 num_beam_groups>1 时,调用 group_beam_search() 方法。
- constrained beam-search decoding:当 constraints!=None 或者 force_words_ids!=None,实现可控文本生成
补充
切片操作
L[-1]取倒数第一个元素,那么它同样支持倒数切片
- L[-2:] 取最后两个元素
1 | L = list(range(100)) |
[1:, 0::2]
- **
1:**:- 这部分表示选择索引从1到数组末尾的所有行。在Python中,索引是从0开始的,所以
1:意味着从第二行开始,一直到数组的最后一行。
- 这部分表示选择索引从1到数组末尾的所有行。在Python中,索引是从0开始的,所以
- **
0::2**:- 这部分表示选择列。这里的
0表示从第一列开始,2表示步长,即每隔一列选择一列。因此,0::2意味着选择所有行的第一列、第三列、第五列等,也就是所有偶数列(如果从1开始计数的话)。
- 这部分表示选择列。这里的
扩充 [] 中的用法
切片操作可以通过不同的参数来灵活选择数组的一部分。以下是一些常见的用法:
- **
start:**:- 选择从
start索引到数组末尾的所有元素。 - 例如,
3:会选择从索引3开始的所有元素。
- 选择从
- **
:start**:- 选择从第一个元素到
start-1索引的所有元素。 - 例如,
:3会选择从索引0到2的元素。
- 选择从第一个元素到
- **
start:stop**:- 选择从
start索引到stop-1索引的所有元素。 - 例如,
1:4会选择从索引1到3的元素。
- 选择从
- **
start:stop:step**:- 选择从
start索引到stop-1索引之间,每隔step个元素选择一个元素。 - 例如,
1:5:2会选择索引1、3的元素。
- 选择从
- **
::step**:- 选择所有元素,每隔
step个元素选择一个元素。 - 例如,
::2会选择索引0、2、4等的元素。
- 选择所有元素,每隔
- **
start::step**:- 选择从
start索引开始的所有元素,每隔step个元素选择一个元素。 - 例如,
2::2会选择索引2、4、6等的元素。
- 选择从
- **
:stop:step**:- 选择从第一个元素到
stop-1索引之间,每隔step个元素选择一个元素。 - 例如,
:4:2会选择索引0、2的元素。
- 选择从第一个元素到
具体例子
假设有一个数组如下:
1 | plaintext |
- **
1:, 0::2**:- 结果:
[[ 4, 6], [ 8, 10], [12, 14]]
- 结果:
- **
:3, :2**:- 结果:
[[ 0, 1], [ 4, 5], [ 8, 9]]
- 结果:
- **
:, 1:3**:- 结果:
[[ 1, 2], [ 5, 6], [ 9, 10], [13, 14]]
- 结果:
- **
2:, ::2**:- 结果:
[[ 8, 9, 10, 11], [12, 13, 14, 15]]
- 结果:
- **
:, 0:3:2**:- 结果:
[[ 0, 2], [ 4, 6], [ 8, 10], [12, 14]]
- 结果:
通过这些切片操作,你可以灵活地选择和操作数组的特定部分。
分布式训练DP和DDP
使用 DDP 进行多卡并行加速模型的重点:
- init_process_group 函数管理进程组
- 在创建 Dataloader 的过程中,需要使用 DistributedSampler 采样器
- 正反向传播之前需要将数据以及模型移动到对应 GPU,通过参数 rank 进行索引,还要将模型使用 DistributedDataParallel 进行包装
- 在每个 epoch 开始之前,需要使用 train_sampler.set_epoch(epoch)为 train_sampler 指定 epoch,这样做可以使每个 epoch 划分给不同进程的 minibatch 不同,从而在整个训练过程中,不同的进程有机会接触到更多的训练数据
- 使用启动器进行启动。不同启动器对应不同的代码。torch.distributed.launch 通过命令行的方法执行,torch.multiprocessing.spawn 则可以直接运行程序
1 | import os |
useful blogs
包括技术分享、时事新闻等
专精ai
前司论坛,比较活跃并且还是有高质量文章
陈浩的个人网站,偏研发相关



